6.2. HTML based Administration Console (Conductor) Guide
Abstract
This section describes how to administer the Virtuoso server from the Conductor interface. It primarily allow users to administer the server while giving access to many of the features that Virtuoso has to offer providing many conceptual demonstrations and introductions.
Most of the pages from the administration interface are provided to help administrators quickly and easily tune the Virtuoso server or navigate the various interfaces and features that Virtuoso has to offer.
6.2.1. Virtuoso Conductor Administration
The Main Navigation Bar provides different tabs that allow you to administrate your Virtuoso server or use one of the provided samples.
Figure 6.1. Navigation
From "System Admin" you can view and change the Conductor Dashboard, manage user accounts; scheduler; Virtuoso Server parameter and Access Control Settings. You can also install /upgrade /uninstall Virtuoso packages and Monitor Virtuoso Server Statistics.
Figure 6.2. System Administration
From "Database" you can administrate your database, manage the Virtuoso Relational Database System, administrate views, tables, stored procedures, trigger definitions, user define types, backups.
Figure 6.3. Database Administration
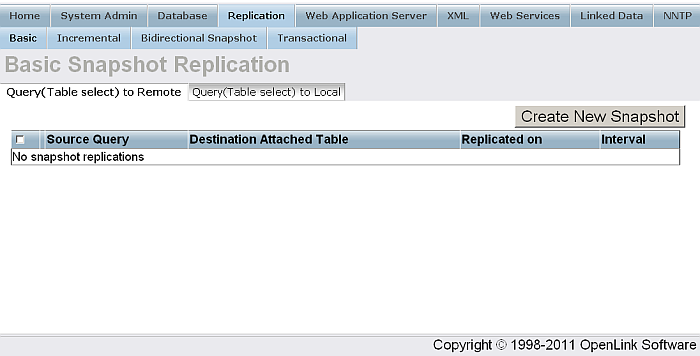
From "Replication" you can create Snapshot Replications to copy sections of the Database to remote locations or use Transactional Replication to keep Virtuoso Servers in sync over a definable interval.
Figure 6.4. Replication
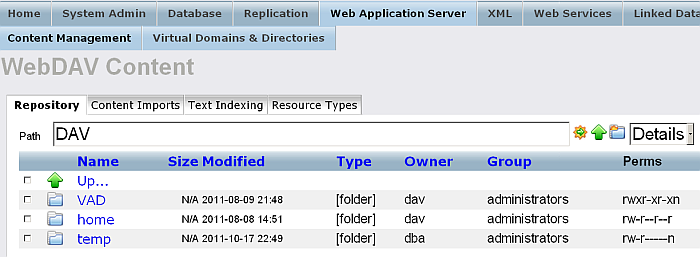
From "Web Application Server" you can configure Virtuoso's WebDAV, and HTTP Server functionality, which includes management of Virtual Domains & Directories.
Figure 6.5. Web Application Server Administration
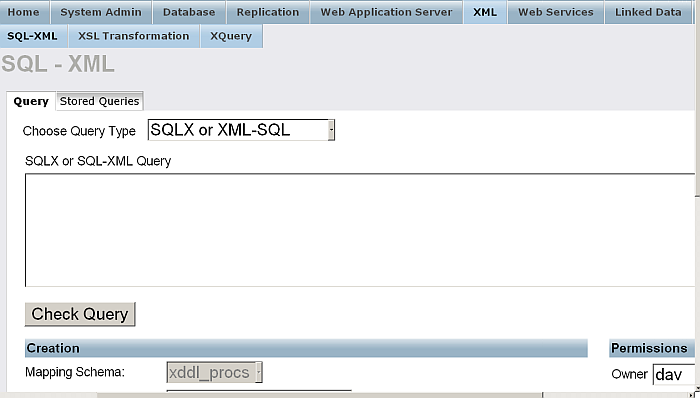
From "XML" you can query Relational and XML Data using SQL, XQUERY, XPATH, and FREE TEXT.
Figure 6.6. Query Tools
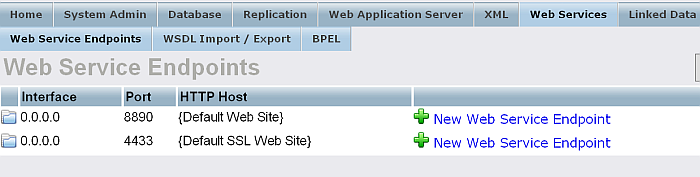
From "Web Services" you can add/ edit/ remove Web Services Endpoints, perform WSDL Import/Export, manage your BPEL processes.
Figure 6.7. Web Services
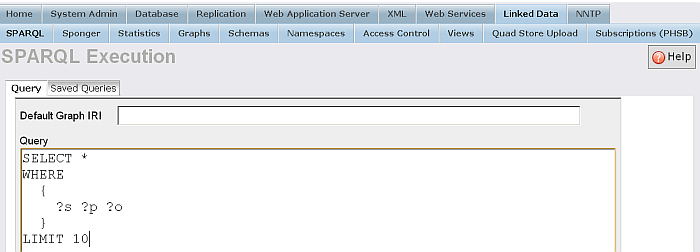
From "Linked Data" tab you can execute/save/load SPARQL queries, add/edit RDF Mapping, make statistics, manage graphs, import schemas and define namespaces, generated Linked Data Views, upload to the Quad Store:
Figure 6.8. RDF
Virtuoso's NNTP support which includes linking third-party NNTP servers into Virtuoso and controlling access to these servers.
Figure 6.9. NNTP Administration