16.3.2.SPARUL -- an Update Language For RDF Graphs
Introduction
Starting with version 5.0, Virtuoso supports the SPARQL/Update extension to SPARQL. This is sufficient for most of routine data manipulation operations. If the SPARQL_UPDATE role is granted to user SPARQL user then data manipulation statements may be executed via the SPARQL web service endpoint as well as by data querying.
Manage RDF Storage
Two functions allow the user to alter RDF storage by inserting
or deleting all triples listed in some vector. Both functions
receive the IRI of the graph that should be altered and a vector of
triples that should be added or removed. The graph IRI can be
either an IRI ID or a string. The third optional argument controls
the transactional behavior - the parameter value is passed to the
log_enable function.
The return values of these functions are not defined and should not
be used by applications.
create function DB.DBA.RDF_INSERT_TRIPLES (in graph_iri any, in triples any, in log_mode integer := null)
create function DB.DBA.RDF_DELETE_TRIPLES (in graph_iri any, in triples any, in log_mode integer := null)
Simple operations may be faster if written as low-level SQL code instead of using SPARUL. The use of SPARQL DELETE is unnecessary in cases where the better alternative is for the application to delete from RDF_QUAD using simple SQL filters like:
DELETE FROM DB.DBA.RDF_QUAD
WHERE G = DB.DBA.RDF_MAKE_IID_OF_QNAME (
'http://local.virt/DAV/sparql_demo/data/data-xml/source-simple2/source-data-01.rdf' );
On the other hand, simple filters does not work when the search criteria refer to triples that are affected by the modification. Consider a function that deletes all triples whose subjects are nodes of type 'http://xmlns.com/foaf/0.1/Person'. Type information is stored in triples that will be deleted, so the simplest function is something like this:
create procedure DELETE_PERSONAL_DATA (in foaf_graph varchar)
{
declare pdata_dict, pdata_array any;
-- Step 1: select everything that should be deleted
pdata_dict := ((
sparql construct { ?s ?p ?o }
WHERE { graph ?:foaf_graph {
?s ?p ?o . ?s rdf:type <http://xmlns.com/foaf/0.1/Person>
} }
));
-- Step 2: delete all found triples
pdata_array := dict_list_keys (pdata_dict, 1);
RDF_DELETE_TRIPLES (foaf_graph, pdata_array);
};
DELETE_PERSONAL_DATA (
'http://local.virt/DAV/sparql_demo/data/data-xml/source-simple2/source-data-01.rdf' );
From Virtuoso 5.0 onwards, applications can use SPARUL to do the same in a more convenient way:
create procedure DELETE_PERSONAL_DATA (in foaf_graph varchar)
{
sparql delete { ?s ?p ?o }
WHERE { graph ?:foaf_graph {
?s ?p ?o . ?s rdf:type <http://xmlns.com/foaf/0.1/Person>
} }
};
Examples
Example for changing the graph
The graph to be changed may be specified by an option preceding of query, instead of being specified in the 'insert into graph' clause.
SQL>SPARQL DEFINE input:default-graph-uri <http://mygraph.com>
INSERT INTO <http://mygraph.com> { <http://example.com/dataspace/Kingsley#this> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://rdfs.org/sioc/ns#User> };
callret-0
VARCHAR
_______________________________________________________________________________
Insert into <http://mygraph.com>, 1 triples -- done
1 Rows. -- 20 msec.
Example for delete graph equivalence
The following two statements are equivalent but the latter may work faster, especially if there are many Linked Data Views in the system or if the graph in question contains triples from Linked Data Views. Note that neither of these two statements affects data coming from Linked Data Views.
SQL> SPARQL DELETE FROM GRAPH <http://mygraph.com> { ?s ?p ?o } FROM <http://mygraph> WHERE { ?s ?p ?o };
callret-0
VARCHAR
_______________________________________________________________________________
Delete from <http://mygraph.com>, 1 triples -- done
1 Rows. -- 10 msec.
SQL> SPARQL CLEAR GRAPH <http://mygraph.com>;
callret-0
VARCHAR
__________________________________________________________
Clear <http://mygraph.com> -- done
1 Rows. -- 10 msec.
DROP GRAPH is equivalent of CLEAR GRAPH. It requires initially the graph to be created explicitly.
Note: All SPARQL commands should work via SPARUL ( i.e. executed from the /sparql endpoint) as soon as "SPARQL" user has "SPARQL_UPDATE" privilege.
Assume the following sequence of commands to be executed from the /sparql endpoint:
-
Create explicitly a graph:
CREATE GRAPH <qq> callret-0 Create graph <qq> -- done
-
If you don't know whether the graph is created explicitly or not, use
DROP SILENT GRAPH
:
DROP SILENT GRAPH <qq> callret-0 Drop silent graph <qq> -- done
-
If you know the graph is created explicitly, use
DROP GRAPH
:
DROP GRAPH <qq> callret-0 Drop graph <qq> -- done
Example for deleting all triples for given subject
The following statement deletes all records with <http://example.com/dataspace/Kingsley#this> as the subject:
SQL>SPARQL
DELETE FROM GRAPH <http://mygraph.com> { ?s ?p ?o }
FROM <http://mygraph.com>
WHERE { ?s ?p ?o . filter ( ?s = <http://example.com/dataspace/Kingsley#this>) };
callret-0
VARCHAR
_______________________________________________________________________________
Delete from <http://mygraph.com>, 1 triples -- done
1 Rows. -- 10 msec.
Alternatively, the statement can be written in this way:
SQL>SPARQL
DELETE FROM GRAPH <http://mygraph.com> { <http://example.com/dataspace/Kingsley#this> ?p ?o }
FROM <http://mygraph.com>
WHERE { <http://example.com/dataspace/Kingsley#this> ?p ?o };
callret-0
VARCHAR
_______________________________________________________________________________
Delete from <http://mygraph.com>, 1 triples -- done
1 Rows. -- 10 msec.
Example for INSERT statements equivalent
Keywords 'insert in' and 'insert into' are interchangeable in Virtuoso for backward compatibility, but the SPARUL specification lists only 'insert into'. For example, the statements below are equivalent:
SQL>SPARQL INSERT INTO GRAPH <http://mygraph.com> { <http://example.com/dataspace/Kingsley#this>
<http://rdfs.org/sioc/ns#id>
<Kingsley> };
callret-0
VARCHAR
______________________________________________________________________________
Insert into <http://mygraph.com>, 1 triples -- done
1 Rows. -- 0 msec.
SQL>SPARQL INSERT INTO GRAPH <http://mygraph.com> { <http://example.com/dataspace/Caroline#this>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://rdfs.org/sioc/ns#User> };
callret-0
VARCHAR
_______________________________________________________________________________
Insert into <http://mygraph.com>, 1 triples -- done
1 Rows. -- 0 msec.
-- and
SQL>SPARQL INSERT IN GRAPH <http://mygraph.com> { <http://example.com/dataspace/Kingsley#this>
<http://rdfs.org/sioc/ns#id>
<Kingsley> };
callret-0
VARCHAR
_______________________________________________________________________________
Insert into <http://mygraph.com>, 1 triples -- done
1 Rows. -- 10 msec.
SQL>SPARQL INSERT IN GRAPH <http://mygraph.com> { <http://example.com/dataspace/Caroline#this>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://rdfs.org/sioc/ns#User> };
callret-0
VARCHAR
________________________________________________________________________
Insert into <http://mygraph.com>, 1 triples -- done
1 Rows. -- 0 msec.
Example for various expressions usage
It is possible to use various expressions to calculate fields of new triples. This is very convenient, even if not a part of the original specification.
SQL>SPARQL INSERT INTO GRAPH <http://mygraph.com> { ?s <http://rdfs.org/sioc/ns#id> `iri (bif:concat (str (?o), "Idehen"))` }
WHERE { ?s <http://rdfs.org/sioc/ns#id> ?o };
callret-0
VARCHAR
_______________________________________________________________________________
Insert into <http://mygraph.com>, 4 triples -- done
1 Rows. -- 0 msec.
Example for operator IN usage
The example shows how to find which predicate/object pairs the following subjects have in common and count the occurances:
http://dbpedia.org/resource/Climate_change http://dbpedia.org/resource/Disaster_risk_reduction http://dbpedia.org/resource/Tanzania http://dbpedia.org/resource/Capacity_building http://dbpedia.org/resource/Poverty http://dbpedia.org/resource/Construction http://dbpedia.org/resource/Vulnerability http://dbpedia.org/resource/Mount_Kilimanjaro http://dbpedia.org/resource/Social_vulnerability
The following query returns the desired results:
SPARQL
SELECT ?s1 ?s2 COUNT (1)
WHERE
{
?s1 ?p ?o .
FILTER (?s1 IN (<http://dbpedia.org/resource/Climate_change>,
<http://dbpedia.org/resource/Disaster_risk_reduction>,
<http://dbpedia.org/resource/Tanzania>,
<http://dbpedia.org/resource/Capacity_building>,
<http://dbpedia.org/resource/Poverty>,
<http://dbpedia.org/resource/Construction>,
<http://dbpedia.org/resource/Vulnerability>,
<http://dbpedia.org/resource/Mount_Kilimanjaro>,
<http://dbpedia.org/resource/Social_vulnerability> ))
?s2 ?p ?o .
FILTER (?s2 IN (<http://dbpedia.org/resource/Climate_change>,
<http://dbpedia.org/resource/Disaster_risk_reduction>,
<http://dbpedia.org/resource/Tanzania>,
<http://dbpedia.org/resource/Capacity_building>,
<http://dbpedia.org/resource/Poverty>,
<http://dbpedia.org/resource/Construction>,
<http://dbpedia.org/resource/Vulnerability>,
<http://dbpedia.org/resource/Mount_Kilimanjaro>,
<http://dbpedia.org/resource/Social_vulnerability> ))
FILTER (?s1 != ?s2)
FILTER (str(?s1) < str (?s2))
}
LIMIT 20
The result of executing the query:
s1 s2 callret-2 http://dbpedia.org/resource/Climate_change http://dbpedia.org/resource/Tanzania 2 http://dbpedia.org/resource/Social_vulnerability http://dbpedia.org/resource/Vulnerability 1 http://dbpedia.org/resource/Mount_Kilimanjaro http://dbpedia.org/resource/Poverty 1 http://dbpedia.org/resource/Mount_Kilimanjaro http://dbpedia.org/resource/Tanzania 3 http://dbpedia.org/resource/Capacity_building http://dbpedia.org/resource/Disaster_risk_reduction 1 http://dbpedia.org/resource/Poverty http://dbpedia.org/resource/Tanzania 1
You can also find live demo query results here
Example for Modify used as Update
'Modify graph' may be used as a form of 'update' operation.
-- update a graph with insert scoped on the same graph
SQL>SPARQL
MODIFY GRAPH <http://mygraph.com>
DELETE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o }
INSERT { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type1> ?o }
FROM <http://mygraph.com>
WHERE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o };
-- update a graph with insert scoped on another graph
SQL>SPARQL
MODIFY GRAPH <http://mygraph.com>
DELETE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o }
INSERT { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type1> ?o }
FROM <http://example.com>
WHERE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o };
-- update a graph with insert scoped over the whole RDF Quad Store
SQL>SPARQL
MODIFY GRAPH <http://mygraph.com>
DELETE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o }
INSERT { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type1> ?o }
WHERE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o };
-- update a graph with delete of particular tripple
SQL>SPARQL
DELETE FROM GRAPH <http://mygraph.com> { <http://example.com/dataspace/Caroline#this> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type1> <http://rdfs.org/sioc/ns#User> };
Example for generating RDF information resource URI
The RDF information resource URI can be generated via a string expression.
-
Suppose there is a sample file kidehen.n3:
<http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com#this> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://rdfs.org/sioc/ns#User> . <http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com#this> <http://www.w3.org/2000/01/rdf-schema#label> "Kingsley" . <http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com#this> <http://rdfs.org/sioc/ns#creator_of> <http://www.openlinksw.com/dataspace/kidehen@openlinksw.com/weblog/kidehen@openlinksw.com%27s%20BLOG%20%5B127%5D/1300> .
-
Using Conductor UI go to Web Application Server and create folder, for ex. with name "n3_collection"
-
Upload the "n3_collection" folder the file kidehen.n3
-
Click properties for the folder "n3_collection" and set to be public readable in the Permissions section
-
Check "Apply changes to all subfolders and resources".
-
Finally Click "Update"
-
Figure16.44.Generating RDF information resource URI
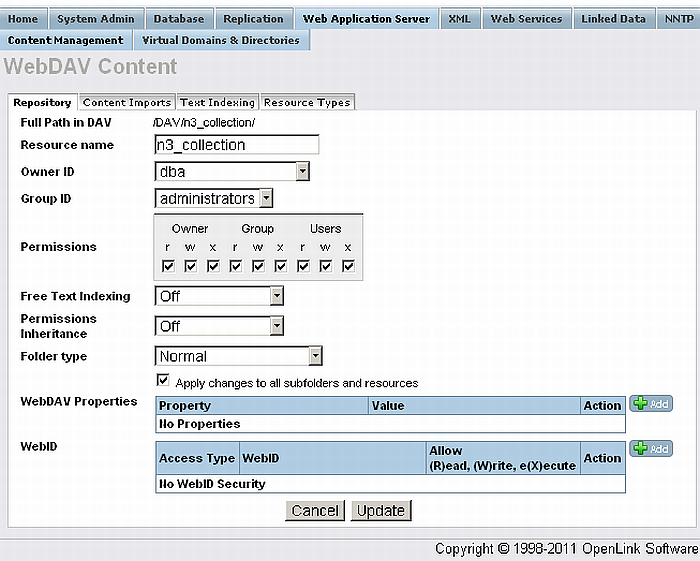
-
To clear the graph execute:
SQL>SPARQL CLEAR GRAPH <http://mygraph.com>; callret-0 VARCHAR _____________________________________________________________________ Clear <http://mygraph.com> -- done 1 Rows. -- 10 msec.
-
To load the kidehen.n3 file execute:
SQL>SPARQL load bif:concat ("http://", bif:registry_get("URIQADefaultHost"), "/DAV/n3_collection/kidehen.n3") INTO GRAPH <http://mygraph.com>; callret-0 VARCHAR _______________________________________________________________________________ Load <http://example.com/DAV/n3_collection/kidehen.n3> into graph <http://mygraph.com> -- done 1 Rows. -- 30 msec. -
In order to check the new inserted triples execute:
SQL>SPARQL SELECT * FROM <http://mygraph.com> WHERE { ?s ?p ?o } ; s p o VARCHAR VARCHAR VARCHAR _______________________________________________________________________________ http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com#this http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://rdfs.org/sioc/ns#User http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com#this http://rdfs.org/sioc/ns#creator_of http://www.openlinksw.com/dataspace/kidehen@openlinksw.com/weblog/kidehen@openlinksw.com%27s%20BLOG%20%5B127%5D/1300 http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com#this http://www.w3.org/2000/01/rdf-schema#label Kingsley 3 Rows. -- 10 msec.
Example for operations over a web service endpoint
Several operations can be sent to a web service endpoint as a single statement and executed in sequence.
SQL>SPARQL
INSERT IN GRAPH <http://mygraph.com> { <http://example.com/dataspace/Kingsley#this>
<http://rdfs.org/sioc/ns#id>
<Kingsley> }
INSERT INTO GRAPH <http://mygraph.com> { <http://example.com/dataspace/Caroline#this>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://rdfs.org/sioc/ns#User> }
INSERT INTO GRAPH <http://mygraph.com> { ?s <http://rdfs.org/sioc/ns#id> `iri (bif:concat (str (?o), "Idehen"))` }
WHERE { ?s <http://rdfs.org/sioc/ns#id> ?o };
callret-0
VARCHAR
_______________________________________________________________________________
Insert into <http://mygraph.com>, 1 triples -- done
Insert into <http://mygraph.com>, 1 triples -- done
Insert into <http://mygraph.com>, 8 triples -- done
Commit -- done
1 Rows. -- 10 msec.
SQL>SPARQL
MODIFY GRAPH <http://mygraph.com>
DELETE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o }
INSERT { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type1> ?o }
FROM <http://mygraph.com>
WHERE { ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?o };
SQL>DELETE FROM GRAPH <http://mygraph.com> { <http://example.com/dataspace/Caroline#this> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type1> <http://rdfs.org/sioc/ns#User> };
SQL>SPARQL
load bif:concat ("http://", bif:registry_get("URIQADefaultHost"), "/DAV/n3_collection/kidehen.n3") INTO GRAPH <http://mygraph.com>;
![[Tip]](images/tip.png) |
See Also: |
|---|---|
Example for Dropping graph
When handling very large RDF data collections (e.g. 600 million triples ) loaded into Virtuoso server as a single graph, the fastest operation to drop the graph is:
SQL>SPARQL CLEAR GRAPH <http://mygraph.com>; callret-0 VARCHAR ______________________________________________________________________________ Clear <http://mygraph.com> -- done 1 Rows. -- 10 msec.
The operation can be speeded up by executing log_enable (0) or even log_enable (2) beforehand, and log_enable(1) after it completes.
Example for testing Graph Equality
The procedure below keeps simple cases of graphs with bnodes:
-
First it compares all triples without bnodes
-
Then it iteratively establishes equivalences between bnodes that are directly and unambiguously connected to equivalent vertexes by identical predicates.
-- Fast Approximate RDF Graph Equivalence Test
-- (C) 2009-2020 OpenLink Software
-- License: GNU General Public License (only version 2 of the license).
-- No warranty, even implied warranty
-- This compares the content of triple dictionaries \c dict1 and \c dict2,
-- returns NULL if no difference found (with bnode equivalence in mind),
-- returns description of a difference otherwise.
-- The function is experimental (note suffix _EXP), so no accurate QA is made.
-- Some version of the function may be inserted later in OpenLink Virtuoso Server under some different name.
create function DB.DBA.RDF_TRIPLE_DICTS_DIFFER_EXP (
in dict1 any, --- Triple dictionary, traditional, (vectors of S, P, O are keys, any non-nulls are values)
in dict2 any, --- Second triple dictionary, like to \c dict1
in accuracy integer, --- Accuracy, 0 if no bnodes expected, 1 if "convenient" trees with intermediate bnodes expected, 2 and more are not yet implemented
in equiv_map any := null, --- If specified then it contain mapping from IRI_IDs of bnodes of \c dict1 to equivalent IRI_IDs of bnodes of \c dict1.
-- It can be extended during the run so use dict_duplicate() before call if needed.
in equiv_rev any := null --- If specified then it is an inverted dictionary of \c equiv_map (this time \c dict2 bnodes are keys and \c dict1 bnodes are values)
)
{
declare dict_size1, dict_size2 integer;
declare old_dirt_level, dirt_level integer;
declare ctr, tailctr, sp_made_new_equiv integer;
declare array1, array2, dict2_sp, dict1_op, dict2_op, array1_op any;
dict_size1 := dict_size (dict1);
dict_size2 := dict_size (dict2);
dict2 := dict_duplicate (dict2);
if (dict_size1 <> dict_size2)
return 'Sizes differ';
if (equiv_map is null)
{
equiv_map := dict_new (dict_size1);
equiv_rev := dict_new (dict_size1);
}
old_dirt_level := dict_size1 - dict_size (equiv_map);
array1 := dict_list_keys (dict1, 0);
next_loop:
-- Step 1: removing triples with all three items matched
ctr := dict_size1-1;
while (ctr >= 0)
{
declare s_in_1, o_in_1, s_in_2, o_in_2, triple_in_2 any;
s_in_1 := array1[ctr][0];
o_in_1 := array1[ctr][2];
if (is_bnode_iri_id (s_in_1))
{
s_in_2 := dict_get (equiv_map, s_in_1, null);
if (s_in_2 is null)
goto next_full_eq_check;
}
else
s_in_2 := s_in_1;
if (is_bnode_iri_id (o_in_1))
{
o_in_2 := dict_get (equiv_map, o_in_1, null);
if (o_in_2 is null)
goto next_full_eq_check;
}
else
o_in_2 := o_in_1;
triple_in_2 := vector (s_in_2, array1[ctr][1], o_in_2);
if (dict_get (dict2, triple_in_2, null) is null)
return vector (array1[ctr], ' is in first, ', triple_in_2, ' is missing in second');
dict_remove (dict2, triple_in_2);
if (ctr < dict_size1-1)
array1[ctr] := array1[dict_size1-1];
dict_size1 := dict_size1-1;
next_full_eq_check:
ctr := ctr-1;
}
-- Step 1 end, garbage truncated:
if ((0 = dict_size1) or (0 = accuracy))
return null;
if (dict_size1 < length (array1))
array1 := subseq (array1, 0, dict_size1);
if (dict_size (dict2) <> dict_size1)
signal ('OBLOM', 'Internal error: sizes of graphs suddenly differ');
-- Step 2: establishing equivs between not-yet-coupled bnodes that are values of functional predicates of coupled subjects
sp_made_new_equiv := 0;
dict2_sp := dict_new (dict_size1);
array2 := dict_list_keys (dict2, 0);
for (ctr := dict_size1-1; ctr >= 0; ctr := ctr-1)
{
declare sp2, o2, prev_uniq_o2 any;
sp2 := vector (array2[ctr][0], array2[ctr][1]);
prev_uniq_o2 := dict_get (dict2_sp, sp2, null);
if (prev_uniq_o2 is null)
{
o2 := array2[ctr][2];
if (is_bnode_iri_id (o2))
dict_put (dict2_sp, sp2, o2);
else
dict_put (dict2_sp, sp2, #i0);
}
else if (prev_uniq_o2 <> #i0)
dict_put (dict2_sp, sp2, #i0);
}
rowvector_subj_sort (array1, 0, 1);
rowvector_subj_sort (array1, 1, 1);
rowvector_subj_sort (array2, 1, 1);
ctr := 0;
while (ctr < dict_size1)
{
declare s_in_1, o_in_1, s_in_2, o_in_2, o_in_dict2_sp, o_in_dict2_sp_in_1 any;
tailctr := ctr+1;
if (array1[ctr][1] <> array2[ctr][1])
{
if (array1[ctr][1] > array2[ctr][1])
return vector ('Cardinality of predicate ', array2[ctr][1], ' is greater in second than in first');
else
return vector ('Cardinality of predicate ', array1[ctr][1], ' is greater in first than in second');
}
while ((tailctr < dict_size1) and
(array1[tailctr][0] = array1[ctr][0]) and
(array1[tailctr][1] = array1[ctr][1]) )
tailctr := tailctr+1;
if ((tailctr - ctr) > 1)
goto next_sp_check;
o_in_1 := array1[ctr][2];
if (not is_bnode_iri_id (o_in_1))
goto next_sp_check;
o_in_2 := dict_get (equiv_map, o_in_1, null);
if (o_in_2 is not null)
goto next_sp_check;
s_in_1 := array1[ctr][0];
if (is_bnode_iri_id (s_in_1))
{
s_in_2 := dict_get (equiv_map, s_in_1, null);
if (s_in_2 is null)
goto next_sp_check;
}
else
s_in_2 := s_in_1;
o_in_dict2_sp := dict_get (dict2_sp, vector (s_in_2, array1[ctr][1]), null);
if (o_in_dict2_sp is null)
return vector (vector (s_in_1, array1[ctr][1], o_in_1), ' is unique SP in first, ', vector (s_in_2, array1[ctr][1]), ' is missing SP in second');
if (o_in_dict2_sp = #i0)
return vector (vector (s_in_1, array1[ctr][1], o_in_1), ' is unique SP in first, ', vector (s_in_2, array1[ctr][1]), ' is not unique SP-to-bnode in second');
o_in_dict2_sp_in_1 := dict_get (equiv_rev, o_in_dict2_sp, null);
if (o_in_dict2_sp_in_1 is not null)
{
if (o_in_dict2_sp_in_1 = o_in_1)
goto next_sp_check;
return vector (vector (s_in_1, array1[ctr][1], o_in_1), ' is unique SP in first, ', vector (s_in_2, array1[ctr][1], o_in_dict2_sp), ' is unique SP in second but ', o_in_dict2_sp, ' rev-equiv to ', o_in_dict2_sp_in_1);
}
dict_put (equiv_map, o_in_1, o_in_dict2_sp);
dict_put (equiv_rev, o_in_dict2_sp, o_in_1);
sp_made_new_equiv := sp_made_new_equiv + 1;
next_sp_check:
ctr := tailctr;
}
dict_list_keys (dict2_sp, 2);
-- Step 2 end
if (sp_made_new_equiv * 10 > dict_size1)
goto next_loop; -- If dictionary is noticeably extended then it's worth to remove more triples before continue.
-- Step 3: establishing equivs between not-yet-coupled bnodes that are subjects of inverse functional properties with coupled objects.
dict1_op := dict_new (dict_size1);
for (ctr := dict_size1-1; ctr >= 0; ctr := ctr-1)
{
declare op1, s1, prev_uniq_s1 any;
op1 := vector (array1[ctr][2], array1[ctr][1]);
prev_uniq_s1 := dict_get (dict1_op, op1, null);
if (prev_uniq_s1 is null)
{
s1 := array1[ctr][0];
if (is_bnode_iri_id (s1))
dict_put (dict1_op, op1, s1);
else
dict_put (dict1_op, op1, #i0);
}
else if (prev_uniq_s1 <> #i0)
dict_put (dict1_op, op1, #i0);
}
array1_op := dict_to_vector (dict1_op, 2);
dict2_op := dict_new (dict_size1);
for (ctr := dict_size1-1; ctr >= 0; ctr := ctr-1)
{
declare op2, s2, prev_uniq_s2 any;
op2 := vector (array2[ctr][2], array2[ctr][1]);
prev_uniq_s2 := dict_get (dict2_op, op2, null);
if (prev_uniq_s2 is null)
{
s2 := array2[ctr][0];
if (is_bnode_iri_id (s2))
dict_put (dict2_op, op2, s2);
else
dict_put (dict2_op, op2, #i0);
}
else if (prev_uniq_s2 <> #i0)
dict_put (dict2_op, op2, #i0);
}
ctr := length (array1_op) - 2;
while (ctr >= 0)
{
declare o_in_1, s_in_1, o_in_2, s_in_2, s_in_dict2_op, s_in_dict2_op_in_1 any;
s_in_1 := array1_op[ctr+1];
if (not is_bnode_iri_id (s_in_1))
goto next_op_check;
s_in_2 := dict_get (equiv_map, s_in_1, null);
if (s_in_2 is not null)
goto next_op_check;
o_in_1 := array1_op[ctr][0];
if (is_bnode_iri_id (o_in_1))
{
o_in_2 := dict_get (equiv_map, o_in_1, null);
if (o_in_2 is null)
goto next_op_check;
}
else
o_in_2 := o_in_1;
s_in_dict2_op := dict_get (dict2_op, vector (o_in_2, array1_op[ctr][1]), null);
if (s_in_dict2_op is null)
return vector (vector (s_in_1, array1_op[ctr][1], o_in_1), ' is unique OP in first, ', vector (o_in_2, array1_op[ctr][1]), ' is missing OP in second');
if (s_in_dict2_op = #i0)
return vector (vector (s_in_1, array1_op[ctr][1], o_in_1), ' is unique OP in first, ', vector (o_in_2, array1_op[ctr][1]), ' is not unique OP-to-bnode in second');
s_in_dict2_op_in_1 := dict_get (equiv_rev, s_in_dict2_op, null);
if (s_in_dict2_op_in_1 is not null)
{
if (s_in_dict2_op_in_1 = s_in_1)
goto next_op_check;
return vector (vector (s_in_1, array1_op[ctr][1], o_in_1), ' is unique OP in first, ', vector (s_in_dict2_op, array1[ctr][1], o_in_2), ' is unique OP in second but ', s_in_dict2_op, ' rev-equiv to ', s_in_dict2_op_in_1);
}
dict_put (equiv_map, s_in_1, s_in_dict2_op);
dict_put (equiv_rev, s_in_dict2_op, s_in_1);
next_op_check:
ctr := ctr - 2;
}
dict_list_keys (dict2_op, 2);
-- Step 3 end
dirt_level := dict_size1 - dict_size (equiv_map);
if (dirt_level >= old_dirt_level)
return vector (vector (array1[0][0], array1[0][1], array1[0][2]), ' has no matches in second with the requested accuracy');
old_dirt_level := dirt_level;
goto next_loop;
}
;
create function DB.DBA.RDF_GRAPHS_DIFFER_EXP (in g1_uri varchar, in g2_uri varchar, in accuracy integer)
{
return DB.DBA.RDF_TRIPLE_DICTS_DIFFER_EXP (
(sparql define output:valmode "LONG" construct { ?s ?p ?o } where { graph `iri(?:g1_uri)` { ?s ?p ?o }}),
(sparql define output:valmode "LONG" construct { ?s ?p ?o } where { graph `iri(?:g2_uri)` { ?s ?p ?o }}),
accuracy );
}
;
-- The rest of file contains some minimal tests.
set verbose off;
set banner off;
set types off;
create function DB.DBA.DICT_EXTEND_WITH_KEYS (in dict any, in keys any)
{
if (dict is null)
dict := dict_new (length (keys));
foreach (any k in keys) do
dict_put (dict, k, 1);
return dict;
}
;
create function DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP (in title varchar, in should_differ integer, in v1 any, in v2 any, in accuracy integer)
{
declare d1, d2, eqm, eqr, differ_status any;
d1 := DB.DBA.DICT_EXTEND_WITH_KEYS (null, v1);
d2 := DB.DBA.DICT_EXTEND_WITH_KEYS (null, v2);
eqm := dict_new (10);
eqr := dict_new (10);
dbg_obj_princ ('===== ' || title);
differ_status := DB.DBA.RDF_TRIPLE_DICTS_DIFFER_EXP (d1, d2, accuracy, eqm, eqr);
dbg_obj_princ ('Result: ', differ_status);
if (0 < dict_size (eqm))
dbg_obj_princ ('Equivalence map: ', dict_to_vector (eqm, 0));
dbg_obj_princ ('Equivalence rev: ', dict_to_vector (eqr, 0));
return sprintf ('%s: %s',
case when (case when should_differ then equ (0, isnull (differ_status)) else isnull (differ_status) end) then 'PASSED' else '***FAILED' end,
title );
}
;
create function DB.DBA.TEST_RDF_GRAPHS_DIFFER_EXP (in title varchar, in should_differ integer, in g1_uri varchar, in g2_uri varchar, in accuracy integer)
{
declare differ_status any;
differ_status := DB.DBA.RDF_GRAPHS_DIFFER_EXP (g1_uri, g2_uri, accuracy);
dbg_obj_princ ('Result: ', differ_status);
return sprintf ('%s: %s',
case when (case when should_differ then equ (0, isnull (differ_status)) else isnull (differ_status) end) then 'PASSED' else '***FAILED' end,
title );
}
;
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'Identical graphs', 0,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i200, 1) ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i200, 1) ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'Sizes differ', 1,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i200, 1) ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i200, 1),
vector (#i101, #i201, #i301) ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'Cardinality of a pred differ', 1,
vector (
vector (#i100, #i200, #ib300),
vector (#i101, #i200, #ib302),
vector (#i103, #i201, #ib304),
vector (#ib109, #i200, #ib109) ),
vector (
vector (#i100, #i200, #ib301),
vector (#i101, #i200, #ib303),
vector (#i103, #i201, #ib305),
vector (#ib109, #i201, #ib109) ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'Bnodes in O with unique SP (equiv)', 0,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib301),
vector (#i101, #i201, #ib301),
vector (#i102, #i202, #ib303),
vector (#ib303, #i204, #i306),
vector (#ib303, #i205, #ib305),
vector (#i100, #i200, 1) ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib302),
vector (#i101, #i201, #ib302),
vector (#i102, #i202, #ib304),
vector (#ib304, #i204, #i306),
vector (#ib304, #i205, #ib306),
vector (#i100, #i200, 1) ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'Bnodes in O with unique SP (diff 1)', 1,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib301),
vector (#i102, #i202, #ib303),
vector (#ib303, #i204, #i306),
vector (#ib303, #i205, #ib305),
vector (#i100, #i200, 1) ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib302),
vector (#i102, #i202, #ib304),
vector (#ib304, #i204, #i306),
vector (#ib304, #i205, #i306),
vector (#i100, #i200, 1) ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'Bnodes in O with unique SP (diff 2)', 1,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib301),
vector (#i102, #i202, #ib303),
vector (#ib303, #i204, #i306),
vector (#ib303, #i205, #ib305),
vector (#i100, #i200, 1) ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib302),
vector (#i102, #i202, #ib304),
vector (#ib304, #i204, #i306),
vector (#ib304, #i205, #ib304),
vector (#i100, #i200, 1) ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'foaf-like-mix (equiv)', 0,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib301),
vector (#i100, #i201, #ib303),
vector (#i100, #i201, #ib305),
vector (#i100, #i201, #ib307),
vector (#ib301, #i202, 'Anna'),
vector (#ib303, #i202, 'Anna'),
vector (#ib305, #i202, 'Brigit'),
vector (#ib307, #i202, 'Clara'),
vector (#ib301, #i203, 'ann@ex.com'),
vector (#ib303, #i203, 'ann@am.com'),
vector (#ib305, #i203, 'root@ple.com'),
vector (#ib307, #i203, 'root@ple.com') ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib302),
vector (#i100, #i201, #ib304),
vector (#i100, #i201, #ib306),
vector (#i100, #i201, #ib308),
vector (#ib302, #i202, 'Anna'),
vector (#ib304, #i202, 'Anna'),
vector (#ib306, #i202, 'Brigit'),
vector (#ib308, #i202, 'Clara'),
vector (#ib302, #i203, 'ann@ex.com'),
vector (#ib304, #i203, 'ann@am.com'),
vector (#ib306, #i203, 'root@ple.com'),
vector (#ib308, #i203, 'root@ple.com') ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'foaf-like-mix (swapped names)', 1,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib301),
vector (#i100, #i201, #ib303),
vector (#i100, #i201, #ib305),
vector (#i100, #i201, #ib307),
vector (#ib301, #i202, 'Anna'),
vector (#ib303, #i202, 'Anna'),
vector (#ib305, #i202, 'Brigit'),
vector (#ib307, #i202, 'Clara'),
vector (#ib301, #i203, 'ann@ex.com'),
vector (#ib303, #i203, 'ann@am.com'),
vector (#ib305, #i203, 'root@ple.com'),
vector (#ib307, #i203, 'root@ple.com') ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib302),
vector (#i100, #i201, #ib304),
vector (#i100, #i201, #ib306),
vector (#i100, #i201, #ib308),
vector (#ib302, #i202, 'Anna'),
vector (#ib304, #i202, 'Brigit'),
vector (#ib306, #i202, 'Anna'),
vector (#ib308, #i202, 'Clara'),
vector (#ib302, #i203, 'ann@ex.com'),
vector (#ib304, #i203, 'ann@am.com'),
vector (#ib306, #i203, 'root@ple.com'),
vector (#ib308, #i203, 'root@ple.com') ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'foaf-like-mix (swapped names)', 1,
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib301),
vector (#i100, #i201, #ib303),
vector (#i100, #i201, #ib305),
vector (#i100, #i201, #ib307),
vector (#ib301, #i202, 'Anna'),
vector (#ib303, #i202, 'Anna'),
vector (#ib305, #i202, 'Brigit'),
vector (#ib307, #i202, 'Clara'),
vector (#ib301, #i203, 'ann@ex.com'),
vector (#ib303, #i203, 'ann@am.com'),
vector (#ib305, #i203, 'root@ple.com'),
vector (#ib307, #i203, 'root@ple.com') ),
vector (
vector (#i100, #i200, #i300),
vector (#i100, #i201, #ib302),
vector (#i100, #i201, #ib304),
vector (#i100, #i201, #ib306),
vector (#i100, #i201, #ib308),
vector (#ib302, #i202, 'Anna'),
vector (#ib304, #i202, 'Brigit'),
vector (#ib306, #i202, 'Anna'),
vector (#ib308, #i202, 'Clara'),
vector (#ib302, #i203, 'ann@ex.com'),
vector (#ib304, #i203, 'ann@am.com'),
vector (#ib306, #i203, 'root@ple.com'),
vector (#ib308, #i203, 'root@ple.com') ),
100
);
select DB.DBA.TEST_RDF_TRIPLE_DICTS_DIFFER_EXP ( 'bnodes only (equiv that can not be proven)', 1,
vector (
vector (#ib101, #i200, #ib103),
vector (#ib103, #i201, #ib101) ),
vector (
vector (#ib102, #i200, #ib104),
vector (#ib104, #i201, #ib102) ),
100
);
sparql clear graph <http://GraphCmp/One>;
TTLP ('@prefix foaf: <http://i-dont-remember-it> .
_:me
a foaf:Person ;
foaf:knows [ foaf:nick "oerling" ; foaf:title "Mr." ; foaf:sha1 "abra" ] ;
foaf:knows [ foaf:nick "kidehen" ; foaf:title "Mr." ; foaf:sha1 "bra" ] ;
foaf:knows [ foaf:nick "aldo" ; foaf:title "Mr." ; foaf:sha1 "cada" ] .',
'', 'http://GraphCmp/One' );
sparql clear graph <http://GraphCmp/Two>;
TTLP ('@prefix foaf: <http://i-dont-remember-it> .
_:iv
foaf:knows [ foaf:title "Mr." ; foaf:sha1 "cada" ; foaf:nick "aldo" ] ;
foaf:knows [ foaf:sha1 "bra" ; foaf:title "Mr." ; foaf:nick "kidehen" ] ;
foaf:knows [ foaf:nick "oerling" ; foaf:sha1 "abra" ; foaf:title "Mr." ] ;
a foaf:Person .',
'', 'http://GraphCmp/Two' );
select DB.DBA.TEST_RDF_GRAPHS_DIFFER_EXP ( 'nonexisting graphs (equiv, of course)', 0,
'http://GraphCmp/NoSuch', 'http://GraphCmp/NoSuch',
100 );
select DB.DBA.TEST_RDF_GRAPHS_DIFFER_EXP ( 'throughout test on foafs (equiv)', 0,
'http://GraphCmp/One', 'http://GraphCmp/Two',
100 );
Example for Adding triples to graph
SQL>SPARQL
INSERT INTO GRAPH <http://BookStore.com>
{ <http://www.dajobe.org/foaf.rdf#i> <http://purl.org/dc/elements/1.1/title> "SPARQL and RDF" .
<http://www.dajobe.org/foaf.rdf#i> <http://purl.org/dc/elements/1.1/date> <1999-01-01T00:00:00>.
<http://www.w3.org/People/Berners-Lee/card#i> <http://purl.org/dc/elements/1.1/title> "Design notes" .
<http://www.w3.org/People/Berners-Lee/card#i> <http://purl.org/dc/elements/1.1/date> <2001-01-01T00:00:00>.
<http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/title> "Fundamentals of Compiler Design" .
<http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/date> <2002-01-01T00:00:00>. };
callret-0
VARCHAR
_________________________________________________________________
Insert into <http://BookStore.com>, 6 triples -- done
1 Rows. -- 0 msec.
Example for Updating triples from graph
A SPARQL/Update request that contains a triple to be deleted and a triple to be added (used here to correct a book title).
SQL>SPARQL
MODIFY GRAPH <http://BookStore.com>
DELETE
{ <http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/title> "Fundamentals of Compiler Design" }
INSERT
{ <http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/title> "Fundamentals" };
callret-0
VARCHAR
_______________________________________________________________________________
Modify <http://BookStore.com>, delete 1 and insert 1 triples -- done
1 Rows. -- 20 msec.
|
See Also: |
|---|---|
Example for Deleting triples from graph
The example below has a request to delete all records of old books (dated before year 2000)
SQL>SPARQL
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
DELETE FROM GRAPH <http://BookStore.com> { ?book ?p ?v }
WHERE
{ GRAPH <http://BookStore.com>
{ ?book dc:date ?date
FILTER ( xsd:dateTime(?date) < xsd:dateTime("2000-01-01T00:00:00")).
?book ?p ?v.
}
};
_______________________________________________________________________________
Delete from <http://BookStore.com>, 6 triples -- done
1 Rows. -- 10 msec.
Example for Copying triples from one graph to another
The next snippet copies records from one named graph to another based on a pattern:
SQL>SPARQL clear graph <http://BookStore.com>;
SQL>SPARQL clear graph <http://NewBookStore.com>;
SQL>SPARQL
insert in graph <http://BookStore.com>
{
<http://www.dajobe.org/foaf.rdf#i> <http://purl.org/dc/elements/1.1/date> <1999-04-01T00:00:00> .
<http://www.w3.org/People/Berners-Lee/card#i> <http://purl.org/dc/elements/1.1/date> <1998-05-03T00:00:00> .
<http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/date> <2001-02-08T00:00:00>
};
SQL>SPARQL
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
INSERT INTO GRAPH <http://NewBookStore.com> { ?book ?p ?v }
WHERE
{ GRAPH <http://BookStore.com>
{ ?book dc:date ?date
FILTER ( xsd:dateTime(?date) > xsd:dateTime("2000-01-01T00:00:00")).
?book ?p ?v.
}
};
callret-0
VARCHAR
_______________________________________________________________________________
Insert into <http://NewBookStore.com>, 6 triples -- done
1 Rows. -- 30 msec.
Example for Moving triples from one graph to another
This example moves records from one named graph to another named graph based on a pattern:
SQL>SPARQL
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
INSERT INTO GRAPH <http://NewBookStore.com>
{ ?book ?p ?v }
WHERE
{ GRAPH <http://BookStore.com>
{ ?book dc:date ?date .
FILTER ( xsd:dateTime(?date) > xsd:dateTime("2000-01-01T00:00:00")).
?book ?p ?v.
}
};
_______________________________________________________________________________
Insert into <http://NewBookStore.com>, 6 triples -- done
1 Rows. -- 10 msec.
SQL>SPARQL
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
DELETE FROM GRAPH <http://BookStore.com>
{ ?book ?p ?v }
WHERE
{ GRAPH <http://BookStore.com>
{ ?book dc:date ?date .
FILTER ( xsd:dateTime(?date) > xsd:dateTime("2000-01-01T00:00:00")).
?book ?p ?v.
}
};
_______________________________________________________________________________
Delete from <http://BookStore.com>, 3 triples -- done
1 Rows. -- 10 msec.
Example for BBC SPARQL Collection
## All programmes related to James Bond:
PREFIX po: <http://purl.org/ontology/po/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?uri ?label
WHERE
{
?uri po:category
<http://www.bbc.co.uk/programmes/people/bmFtZS9ib25kLCBqYW1lcyAobm8gcXVhbGlmaWVyKQ#person> ;
rdfs:label ?label.
}
## Find all Eastenders broadcasta after 2009-01-01,
## along with the broadcast version & type
PREFIX event: <http://purl.org/NET/c4dm/event.owl#>
PREFIX tl: <http://purl.org/NET/c4dm/timeline.owl#>
PREFIX po: <http://purl.org/ontology/po/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?version_type ?broadcast_start
WHERE
{
<http://www.bbc.co.uk/programmes/b006m86d#programme> po:episode ?episode .
?episode po:version ?version .
?version a ?version_type .
?broadcast po:broadcast_of ?version .
?broadcast event:time ?time .
?time tl:start ?broadcast_start .
FILTER ( (?version_type != <http://purl.org/ontology/po/Version>)
&& (?broadcast_start > "2009-01-01T00:00:00Z"^^xsd:dateTime) )
}
## Find all programmes that featured both the Foo Fighters and Al Green
PREFIX po: <http://purl.org/ontology/po/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX mo: <http://purl.org/ontology/mo/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX event: <http://purl.org/NET/c4dm/event.owl#>
PREFIX tl: <http://purl.org/NET/c4dm/timeline.owl#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
SELECT DISTINCT ?programme ?label
WHERE
{
?event1 po:track ?track1 .
?track1 foaf:maker ?maker1 .
?maker1 owl:sameAs
<http://www.bbc.co.uk/music/artists/67f66c07-6e61-4026-ade5-7e782fad3a5d#artist> .
?event2 po:track ?track2 .
?track2 foaf:maker ?maker2 .
?maker2 owl:sameAs
<http://www.bbc.co.uk/music/artists/fb7272ba-f130-4f0a-934d-6eeea4c18c9a#artist> .
?event1 event:time ?t1 .
?event2 event:time ?t2 .
?t1 tl:timeline ?tl .
?t2 tl:timeline ?tl .
?version po:time ?t .
?t tl:timeline ?tl .
?programme po:version ?version .
?programme rdfs:label ?label .
}
## Get short synopsis' of EastEnders episodes
PREFIX po: <http://purl.org/ontology/po/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?t ?o
WHERE
{
<http://www.bbc.co.uk/programmes/b006m86d#programme> po:episode ?e .
?e a po:Episode .
?e po:short_synopsis ?o .
?e dc:title ?t
}
## Get short synopsis' of EastEnders episodes (with graph)
PREFIX po: <http://purl.org/ontology/po/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?g ?t ?o
WHERE
{
graph ?g
{
<http://www.bbc.co.uk/programmes/b006m86d#programme> po:episode ?e .
?e a po:Episode .
?e po:short_synopsis ?o .
?e dc:title ?t
}
}
## Get reviews where John Paul Jones' has been involved
PREFIX mo: <http://purl.org/ontology/mo/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rev: <http://purl.org/stuff/rev#>
PREFIX po: <http://purl.org/ontology/po/>
SELECT DISTINCT ?r_name, ?rev
WHERE
{
{
<http://www.bbc.co.uk/music/artists/4490113a-3880-4f5b-a39b-105bfceaed04#artist> foaf:made ?r1 .
?r1 a mo:Record .
?r1 dc:title ?r_name .
?r1 rev:hasReview ?rev
}
UNION
{
<http://www.bbc.co.uk/music/artists/4490113a-3880-4f5b-a39b-105bfceaed04#artist> mo:member_of ?b1 .
?b1 foaf:made ?r1 .
?r1 a mo:Record .
?r1 dc:title ?r_name .
?r1 rev:hasReview ?rev
}
}
Example usage of IN operator for retrieving all triples for each entity
To retrieve all triples for each entity for a given list of entities uris, one might use the following syntax:
SELECT ?p ?o
WHERE
{
?s ?p ?o .
FILTER ( ?s IN (<someGraph#entity1>, <someGraph#entity2>, ...<someGraph#entityN> ) )
}
So to demonstrate this feature, execute the following query:
SQL>SPARQL
SELECT DISTINCT ?p ?o
WHERE
{
?s ?p ?o .
FILTER ( ?s IN (<http://dbpedia.org/resource/Climate_change>, <http://dbpedia.org/resource/Social_vulnerability> ) )
}
LIMIT 100
p o
ANY ANY
_______________________________________________________________________________
http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://s.zemanta.com/ns#Target
http://s.zemanta.com/ns#title Climate change
http://s.zemanta.com/ns#targetType http://s.zemanta.com/targets#rdf
3 Rows. -- 10 msec.
|
See Also: |
|---|---|
Example for extending SPARQL via SQL for Full Text search: Variant I
To find all albums looked up by album name, one might use the following syntax:
SQL>SPARQL
SELECT ?s ?o ?an ( bif:search_excerpt ( bif:vector ( 'In', 'Your' ) , ?o ) )
WHERE
{
?s rdf:type mo:Record .
?s foaf:maker ?a .
?a foaf:name ?an .
?s dc:title ?o .
FILTER ( bif:contains ( ?o, '"in your"' ) )
}
LIMIT 10;
http://musicbrainz.org/music/record/30f13688-b9ca-4fa5-9430-f918e2df6fc4 China in Your Hand Fusion China <b>in</b> <b>Your</b> Hand.
http://musicbrainz.org/music/record/421ad738-2582-4512-b41e-0bc541433fbc China in Your Hand T'Pau China <b>in</b> <b>Your</b> Hand.
http://musicbrainz.org/music/record/01acff2a-8316-4d4b-af93-97289e164379 China in Your Hand T'Pau China <b>in</b> <b>Your</b> Hand.
http://musicbrainz.org/music/record/4fe99b06-ac73-40dd-8be7-bdaefb014981 China in Your Hand T'Pau China <b>in</b> <b>Your</b> Hand.
http://musicbrainz.org/music/record/ac1cb011-6040-4515-baf2-59551a9884ac In Your Hands Stella One Eleven <b>In</b> <b>Your</b> Hands.
http://dbtune.org/magnatune/album/mercy-inbedinst In Your Bed - instrumental mix Mercy Machine <b>In</b> <b>Your</b> Bed mix.
http://musicbrainz.org/music/record/a09ae12e-3694-4f68-bf25-f6ff4f790962 A Word in Your Ear Alfie A Word <b>in</b> <b>Your</b> Ear.
http://dbtune.org/magnatune/album/mercy-inbedremix In Your Bed - the remixes Mercy Machine <b>In</b> <b>Your</b> Bed the remixes.
http://musicbrainz.org/music/record/176b6626-2a25-42a7-8f1d-df98bec092b4 Smoke Gets in Your Eyes The Platters Smoke Gets <b>in</b> <b>Your</b> Eyes.
http://musicbrainz.org/music/record/e617d90e-4f86-425c-ab97-efdf4a8a452b Smoke Gets in Your Eyes The Platters Smoke Gets <b>in</b> <b>Your</b> Eyes.
Note that the query will not show anything when there are triples like:
<x> <y> "In" <z> <q> "Your"
Example for extending SPARQL via SQL for Full Text search: Variant II
To get movies from DBpedia, where the query can contain terms from the title, one might use the following syntax:
SQL>SPARQL
SELECT ?s ?an ?dn ?o( bif:search_excerpt ( bif:vector ( 'Broken', 'Flowers' ) , ?o ) )
WHERE
{
?s rdf:type dbpedia-owl:Film .
?s dbpprop:name ?o .
FILTER ( bif:contains ( ?o, '"broken flowers"' ) )
OPTIONAL { ?s dbpprop:starring ?starring .}
OPTIONAL { ?s dbpprop:director ?director . }
OPTIONAL { ?starring dbpprop:name ?an . }
OPTIONAL { ?director dbpprop:name ?dn . }
};
http://dbpedia.org/resource/Broken_Flowers Tilda Swinton Jim Jarmusch Broken Flowers <b>Broken</b> <b>Flowers</b>.
http://dbpedia.org/resource/Broken_Flowers Swinton, Tilda Jim Jarmusch Broken Flowers <b>Broken</b> <b>Flowers</b>.
....
http://dbpedia.org/resource/Broken_Flowers Bill Murray Jim Jarmusch Music from Broken Flowers Music from <b>Broken</b> <b>Flowers</b>.
....
Note that the query will not show anything when there are triples like:
<x> <y> "Broken" <z> <q> "Flowers"
Example for date manipulation of xsd types within SPARQL
This example shows usage of dateTime column truncation to date only and performs a group by on this column:
-- prepare the data by inserting triples in a graph:
SQL>SPARQL
INSERT INTO GRAPH <http://BookStore.com>
{
<http://www.dajobe.org/foaf.rdf#i> <http://purl.org/dc/elements/1.1/title> "SPARQL and RDF" .
<http://www.dajobe.org/foaf.rdf#i> <http://purl.org/dc/elements/1.1/date> <1999-01-01T00:00:00>.
<http://www.w3.org/People/Berners-Lee/card#i> <http://purl.org/dc/elements/1.1/title> "Design notes" .
<http://www.w3.org/People/Berners-Lee/card#i> <http://purl.org/dc/elements/1.1/date> <2001-01-01T00:00:00>.
<http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/title> "Fundamentals of Compiler Design" .
<http://www.w3.org/People/Connolly/#me> <http://purl.org/dc/elements/1.1/date> <2002-01-01T00:00:00>.
<http://www.ivan-herman.net/foaf.rdf#me> <http://purl.org/dc/elements/1.1/title> "RDF Store" .
<http://www.ivan-herman.net/foaf.rdf#me> <http://purl.org/dc/elements/1.1/date> <2001-03-05T00:00:00>.
<http://bblfish.net/people/henry/card#me> <http://purl.org/dc/elements/1.1/title> "Design RDF notes" .
<http://bblfish.net/people/henry/card#me> <http://purl.org/dc/elements/1.1/date> <2001-01-01T00:00:00>.
<http://hometown.aol.com/chbussler/foaf/chbussler.foaf#me> <http://purl.org/dc/elements/1.1/title> "RDF Fundamentals" .
<http://hometown.aol.com/chbussler/foaf/chbussler.foaf#me> <http://purl.org/dc/elements/1.1/date> <2002-01-01T00:00:00>.
};
_______________________________________________________
Insert into <http://BookStore.com>, 12 triples -- done
-- Find Count of Group by Dates
SQL>SPARQL
SELECT (xsd:date(bif:subseq(str(?a_dt), 0, 10))), count(*)
FROM <http://BookStore.com>
WHERE
{
?s <http://purl.org/dc/elements/1.1/date> ?a_dt
}
GROUP BY (xsd:date(bif:subseq(str(?a_dt), 0, 10)));
callret-0 callret-1
VARCHAR VARCHAR
__________________________________________________
1999-01-01 1
2001-01-01 2
2002-01-01 2
2001-03-05 1
4 Rows. -- 15 msec.
SQL>
Example for executing INSERT/DELETE (SPARUL) statements against a WebID protected SPARQL endpoint
The following sample scenario demonstrates how to perform INSERT/DELETE (SPARUL) statements against a protected SPARQL Endpoint by setting WebID Protocol ACLs using the Virtuoso Authentication Server UI:
-
Obtain a WebID:
-
Download and install the ods_framework_dav.vad .
-
Note: an existing ODS DataSpace user instance can also be used, for example at http://id.myopenlink.net/ods/
-
-
Register an ODS Data Space user, for example with name "demo".
-
The generated WebID will be for example:
http://id.myopenlink.net/dataspace/person/demo#this
-
Generate a Personal HTTP based Identifier for the "demo" user and then bind the personal Identifier to an X.509 Certificate, thereby giving assigning the user a WebID.
-
-
Download and install the conductor_dav.vad package, if not already installed.
-
Go to http://<cname>:<port>/conductor, where <cname>:<port> are replaced by your local server values.
-
Go to System Admin -> Linked Data -> Access Control -> SPARQL-WebID
Figure16.45.Conductor SPARQL-WebID
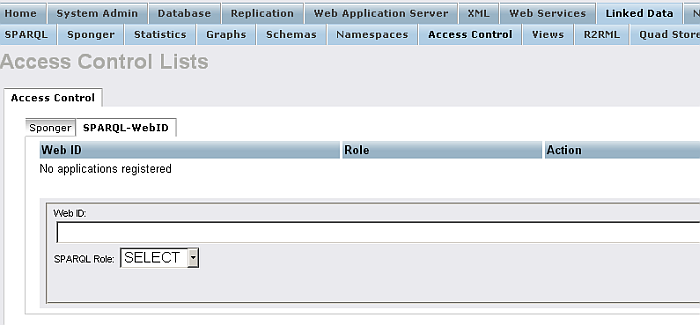
-
In the displayed form:
-
Enter the Web ID for the user registered above, for example:
http://id.myopenlink.net/dataspace/person/demo#this
-
Select "SPARQL Role": "
UPDATE
".
Figure16.46.Conductor SPARQL-WebID
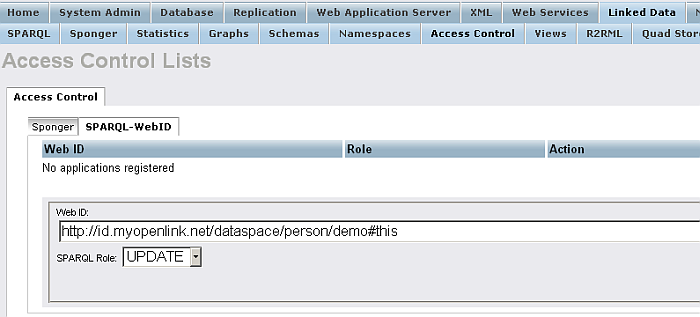
-
-
Click the "Register" button.
-
The WebID Protocol ACL will be created:
Figure16.47.Conductor SPARQL-WebID
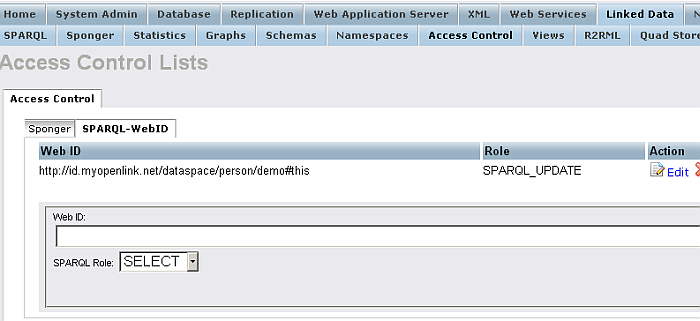
-
Go to the SPARQL-WebID endpoint, https://<cname>:<port>/sparql-webid, where <cname>:<port> are replaced by your local server values.
-
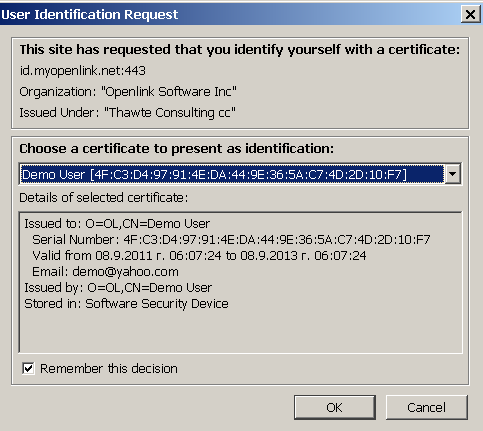
Select the user's certificate:
Figure16.48.Conductor SPARQL-WebID
-
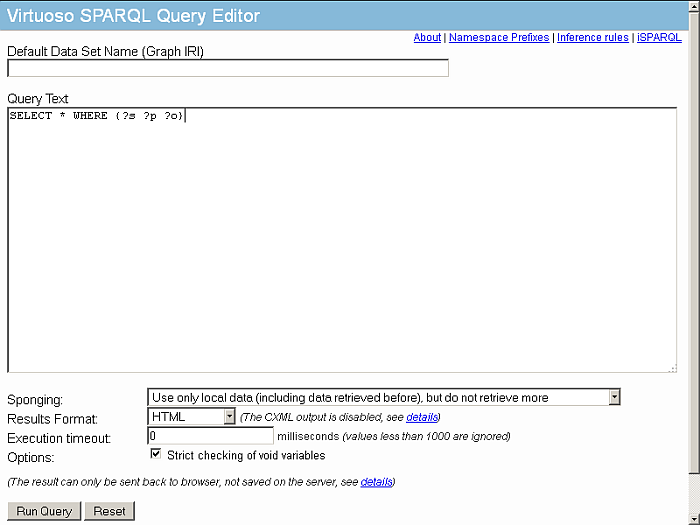
The SPARQL Query UI will be displayed:
Figure16.49.Conductor SPARQL-WebID
-
Execute the query:
INSERT INTO GRAPH <http://example.com> { <s1> <p1> <o1> . <s2> <p2> <o2> . <s3> <p3> <o3> }Figure16.50.Conductor SPARQL-WebID
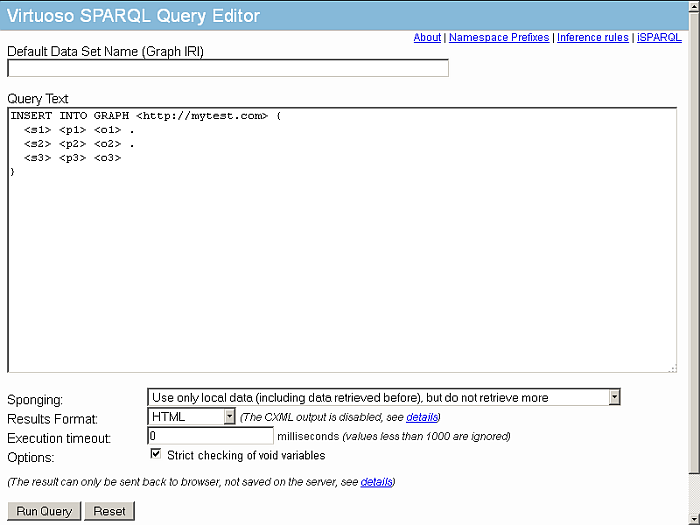
Figure16.51.Conductor SPARQL-WebID
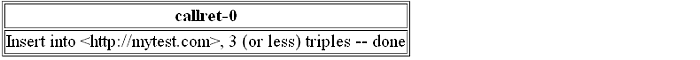
Note: If the SPARQL Role "Sponge" is set instead, in order to be able to execute DELETE/INSERT statements over the protected SPARQL Endpoint, the following grants need to be performed for the user, associated with the WebID ACL Role:
grant execute on DB.DBA.SPARQL_INSERT_DICT_CONTENT to "demo"; grant execute on DB.DBA.SPARQL_DELETE_DICT_CONTENT to "demo";
Example usage of deleting Triple Patterns that are Not Scoped to a Named Graph
Presuming this triple exists in one or more graphs in the store:
{
<http://kingsley.idehen.net/dataspace/person/kidehen#this>
<http://xmlns.com/foaf/0.1/knows>
<http://id.myopenlink.net/dataspace/person/KingsleyUyiIdehen#this>
}
The SQL query below will delete that triple from all graphs in the store:
DELETE
FROM DB.DBA.RDF_QUAD
WHERE p = iri_to_id
('http://xmlns.com/foaf/0.1/knows')
AND s = iri_to_id
('http://kingsley.idehen.net/dataspace/person/kidehen#this')
AND o = iri_to_id
('http://id.myopenlink.net/dataspace/person/KingsleyUyiIdehen#this')
;
According to SPARQL 1.1 Update , the FROM clause which scopes the query to a single graph is optional. Thus, the SQL query above can be rewritten to the SPARQL query below, again deleting the matching triple from all graphs in the store:
DELETE
{
GRAPH ?g
{
<http://kingsley.idehen.net/dataspace/person/kidehen#this>
<http://xmlns.com/foaf/0.1/knows>
<http://id.myopenlink.net/dataspace/person/KingsleyUyiIdehen#this>
}
}
WHERE
{
GRAPH ?g
{
<http://kingsley.idehen.net/dataspace/person/kidehen#this>
<http://xmlns.com/foaf/0.1/knows>
<http://id.myopenlink.net/dataspace/person/KingsleyUyiIdehen#this>
}
}
Example usage of deleting triples containing blank nodes
There are two ways to delete a particular blank node:
-
To refer to it via some properties or:
-
To convert it to it's internal "serial number", a long integer, and back.
Assume the following sample scenario:
-
Clear the graph:
SPARQL CLEAR GRAPH <http://sample/>; Done. -- 4 msec.
-
Insert three blank nodes with two related triples each:
SPARQL INSERT IN GRAPH <http://sample/> { [] <p> <o1a> , <o1b> . [] <p> <o2a> , <o2b> . [] <p> <o3a> , <o3b> } Done. -- 15 msec. -
Delete one pair of triples:
SPARQL WITH <http://sample/> DELETE { ?s ?p ?o } WHERE { ?s ?p ?o ; <p> <o1a> . } Done. -- 7 msec. -
Ensure that we still have two bnodes, two triple per bnode:
SPARQL SELECT * FROM <http://sample/> WHERE { ?s ?p ?o } s p o VARCHAR VARCHAR VARCHAR ________________ nodeID://b10006 p o3a nodeID://b10006 p o3b nodeID://b10007 p o2a nodeID://b10007 p o2b 4 Rows. -- 4 msec. -
-
Each bnode, as well as any "named" node, is identified internally as an integer:
SPARQL SELECT (<LONG::bif:iri_id_num>(?s)) AS ?s_num, ?p, ?o FROM <http://sample/> WHERE { ?s ?p ?o }; s_num p o INTEGER VARCHAR VARCHAR _____________________________ 4611686018427397910 p o3a 4611686018427397910 p o3b 4611686018427397911 p o2a 4611686018427397911 p o2b 4 Rows. -- 5 msec. -
The integer can be converted back to internal identifier. Say, here we try to delete a triple that does not exist (even if the ID integer is valid):
SPARQL DELETE FROM <http://sample/> { `bif:iri_id_from_num(4611686018427397911)` <p> <o3a> }; Done. -- 5 msec. -
Should have no effect, because the "46..11" IRI has <o2a> and <o2b>, and was not requested <o3a>:
SPARQL SELECT * FROM <http://sample/> WHERE { ?s ?p ?o }; s p o VARCHAR VARCHAR VARCHAR ________________ nodeID://b10006 p o3a nodeID://b10006 p o3b nodeID://b10007 p o2a nodeID://b10007 p o2b 4 Rows. -- 5 msec. -
Now let's try to delete a triple that does actually exist. Note the use of backquotes to insert an expression into template:
SPARQL DELETE FROM <http://sample/> { `bif:iri_id_from_num(4611686018427397911)` <p> <o2a> }; Done. -- 4 msec. -
So there's an effect:
SPARQL SELECT * FROM <http://sample/> WHERE { ?s ?p ?o }; s p o VARCHAR VARCHAR VARCHAR _________________ nodeID://b10006 p o3a nodeID://b10006 p o3b nodeID://b10007 p o2b 3 Rows. -- 2 msec. -
Now delete everything related to
nodeID://b10006subject:SPARQL WITH <http://sample/> DELETE { ?s ?p ?o } WHERE { ?s ?p ?o . FILTER (?s = bif:iri_id_from_num(4611686018427397910)) }; Done. -- 18 msec. -
Three minus two gives one triple remaining:
SQL> SPARQL SELECT * FROM <http://sample/> WHERE { ?s ?p ?o }; s p o VARCHAR VARCHAR VARCHAR _________________ nodeID://b10007 p o2b 1 Rows. -- 4 msec.
Note
: IDs of bnodes will
vary from server to server and even from run to run on the same
server, so the application should identify bnodes by properties
before doing bif:iri_id_XXX tricks.
Example usage of expressions inside CONSTRUCT, INSERT and DELETE {...} Templates
When one wants to use expressions inside CONSTRUCT {...}, INSERT {...} or DELETE {...} construction templates, the expressions should be in back-quotes i.e:
`expression`
Why?
The are times when you need to post-process existing RDF triples en route to creating enhanced data views. For instance, enhancing the literal values associated with annotation properties such as rdfs:label and rdfs:comment .
Why?
Here some SPARQL 1.1 Update Language examples showcasing how this is achieved using Virtuoso.
Example usage of expression inside CONSTRUCT
CONSTRUCT
{
?inst rdfs:label `bif:concat ( ?inst_label,
" Instance with up to ",
str(?core_val),
" logical processor cores and " ,
str(?sess_val) , " concurrent ODBC sessions from licensed host" )`
}
FROM <http://uda.openlinksw.com/pricing/>
WHERE
{
?inst a gr:Individual, oplweb:ProductLicense ;
rdfs:label ?inst_label ;
oplweb:hasMaximumProcessorCores ?core ;
oplweb:hasSessions ?sess .
?core a gr:QuantitativeValueInteger ;
gr:hasMaxValueInteger ?core_val .
?sess a gr:QuantitativeValueInteger ;
gr:hasValue ?sess_val .
}
See live results of the query.
Example usage of expression inside INSERT
SPARQL
INSERT INTO GRAPH <urn:mygraph>
{
?inst rdfs:label `bif:concat ( ?inst_label,
" Instance with up to ",
str(?core_val),
" logical processor cores and " ,
str(?sess_val) ,
" concurrent ODBC sessions from licensed host" )`
}
FROM <http://uda.openlinksw.com/pricing/>
WHERE
{
?inst a gr:Individual, oplweb:ProductLicense ;
rdfs:label ?inst_label ;
oplweb:hasMaximumProcessorCores ?core ;
oplweb:hasSessions ?sess .
?core a gr:QuantitativeValueInteger ;
gr:hasMaxValueInteger ?core_val .
?sess a gr:QuantitativeValueInteger ;
gr:hasValue ?sess_val .
};
Done. -- 406 msec.
SQL> SPARQL
SELECT ?label
FROM <urn:mygraph>
WHERE
{
?inst rdfs:label ?label
};
label
VARCHAR
_______________________________________________________________________________
ODBC Driver (Single-Tier Lite Express Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
ODBC Driver (Single-Tier Lite Express Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
JDBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
OLEDB Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
ADO.NET Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor cores and 5 concurrent ODBC sessions from licensed host
9 Rows. -- 31 msec.
Example usage of expression inside DELETE
SPARQL
DELETE FROM GRAPH <urn:mygraph>
{ ?inst rdfs:label `bif:concat ( "JDBC Driver (Single-Tier Lite Edition) Instance with up to ", str(?core_val), " logical processor cores and " , str(?sess_val) , " concurrent ODBC sessions from licensed host" )` }
FROM <http://uda.openlinksw.com/pricing/>
WHERE
{
?inst a gr:Individual, oplweb:ProductLicense ;
rdfs:label ?inst_label ;
oplweb:hasMaximumProcessorCores ?core ;
oplweb:hasSessions ?sess .
filter (regex(?inst_label,"JDBC Driver")) .
?core a gr:QuantitativeValueInteger ;
gr:hasMaxValueInteger ?core_val .
?sess a gr:QuantitativeValueInteger ;
gr:hasValue ?sess_val .
}
;
Done. -- 32 msec.
SQL> SPARQL
SELECT ?label
FROM <urn:mygraph>
WHERE
{
?inst rdfs:label ?label
};
label
VARCHAR
_______________________________________________________________________________
ODBC Driver (Single-Tier Lite Express Edition) Instance with up to 16 logical ...
ODBC Driver (Single-Tier Lite Express Edition) Instance with up to 16 logical ...
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor ...
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor ...
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor ...
ODBC Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor ...
OLEDB Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor ...
ADO.NET Driver (Single-Tier Lite Edition) Instance with up to 16 logical processor ...
8 Rows. -- 16 msec.