16.13.3. URL rewriting
URL rewriting is the act of modifying a source URL prior to the final processing of that URL by a Web Server.
The ability to rewrite URLs may be desirable for many reasons that include:
-
Changing Web information resource URLs on the a Web Server without breaking existing bookmarks held in User Agents (e.g., Web browsers)
-
URL compaction where shorter URLs may be constructed on a conditional basis for specific User Agents (e.g. Email clients)
-
Construction of search engine friendly URLs that enable richer indexing since most search engines cannot process parameterized URLs effectively.
Using URL Rewriting to Solve Linked Data Deployment Challenges
URI naming schemes don't resolve the challenges associated with referencing data. To reiterate, this is demonstrated by the fact that the URIs http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this both appear as http://demo.openlinksw.com/Northwind/Customer/ALFKI to the Web Server, since data following the fragment identifier "#" never makes it that far.
The only way to address data referencing is by pre-processing source URIs (e.g. via regular expression or sprintf substitutions) as part of a URL rewriting processing pipeline. The pipeline process has to take the form of a set of rules that cater for elements such as HTTP Accept headers, HTTP response code, HTTP response headers, and rule processing order.
An example of such a pipeline is depicted in the table below.
Table 16.17. Pre-processing source URIs
| URI Source(Regular Expression Pattern) | HTTP Accept Headers(Regular Expression) | HTTPResponse Code | HTTP Response Headers | Rule Processing Order |
|---|---|---|---|---|
| /Northwind/Customer/([^#]*) | None (meaning default) | 200 or 303 redirect to a resource with default representation. | None | Normal (order irrelevant) |
| /Northwind/Customer/([^#]*) | (text/rdf.n3) | (application/rdf.xml) | 303 redirect to location of a descriptive and associated resource (e.g. RESTful Web Service that returns desired representation) | None |
| /Northwind/Customer/([^#]*) | (text/html) | (application/xhtml.xml) | 406 (Not Acceptable)or303 redirect to location of resource in requested representation | Vary: negotiate, acceptAlternates: {"ALFKI" 0.9 {type application/rdf+xml}} |
The source URI patterns refer to virtual or physical directories for ex. at http://demo.openlinksw.com/. Rules can be placed at the head or tail of the pipeline, or applied in the order they are declared, by specifying a Rule Processing Order of First, Last, or Normal, respectively. The decision as to which representation to return for URI http://demo.openlinksw.com/Northwind/Customer/ALFKI is based on the MIME type(s) specified in any Accept header accompanying the request.
In the case of the last rule, the Alternates response header applies only to response code 406. 406 would be returned if there were no (X)HTML representation available for the requested resource. In the example shown, an alternative representation is available in RDF/XML.
When applied to matching HTTP requests, the last two rules might generate responses similar to those below:
$ curl -I -H "Accept: application/rdf+xml" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 303 See Other
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Mon, 16 Jul 2007 22:40:03 GMT
Accept-Ranges: bytes
Location: /sparql?query=CONSTRUCT+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}+FROM+%3Chttp%3A//demo.openlinksw.com/Northwind%3E+WHERE+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}&format=application/rdf%2Bxml
Content-Length: 0
In the cURL exchange depicted above, the target Virtuoso server redirects to a SPARQL endpoint that retrieves an RDF/XML representation of the requested entity.
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 406 Not Acceptable
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Mon, 16 Jul 2007 22:40:23 GMT
Accept-Ranges: bytes
Vary: negotiate,accept
Alternates: {"ALFKI" 0.9 {type application/rdf+xml}}
Content-Length: 0
In this second cURL exchange, the target Virtuoso server indicates that there is no resource to deliver in the requested representation. It provides hints in the form of an alternate resource representation and URI that may be appropriate, i.e., an RDF/XML representation of the requested entity.
The Virtuoso Rules-Based URL Rewriter
Virtuoso provides a URL rewriter that can be enabled for URLs matching specified patterns. Coupled with customizable HTTP response headers and response codes, Data-Web server administrators can configure highly flexible rules for driving content negotiation and URL rewriting. The key elements of the URL rewriter are:
-
Rewriting rule
-
Each rule describes how to parse a single source URL, and how to compose the URL of the page ultimately returned in the "Location:" response headers
-
Every rewriting rule is uniquely identified internally (using IRIs).
-
Two types of rule are supported, based on the syntax used to describe the source URL pattern matching: sprintf-based and regex-based.
-
Rewrite rules list
-
A named ordered list of rewrite rules or rule lists where rules of the list are processed from top to bottom or in line with processing pipeline precedence instructions
-
Configuration API
-
The rewriter configuration API defines functions for creating, dropping, and enumerating rules and rule lists.
-
Virtual hosts and virtual paths
-
URL rewriting is enabled by associating a rewrite rules list with a virtual directory
Virtual Domains (Hosts) & Directories
A Virtuoso virtual directory maps a logical path to a physical directory that is file system or WebDAV based. This mechanism allows physical locations to be hidden or simply reorganised. Virtual directory definitions are held in the system table DB.DBA.HTTP_PATH. Virtual directories can be administered in three basic ways:
-
Using the Visual Administration Interface via a Web browser;
-
Using the functions vhost_define() and vhost_remove(); and
-
Using SQL statements to directly update the HTTP_PATH system table.
"Nice" URLs vs. "Long" URLs
Although we are approaching the URL Rewriter from the perspective of deploying linked data, the Rewriter was developed with additional objectives in mind. These in turn have influenced the naming of some of the formal argument names in the Configuration API function prototypes. In the following sections, long URLs are those containing a query string with named parameters; nice (aka. source) URLs have data encoded in some other format. The primary goal of the Rewriter is to accept a nice URL from an application and convert this into a long URL, which then identifies the page that should actually be retrieved.
Rule Processing Mechanics
When an HTTP request is accepted by the Virtuoso HTTP server, the received nice URL is passed to an internal path translation function. This function takes the nice URL and, if the current virtual directory has a url_rewrite option set to an existing ruleset name, tries to match the corresponding rulesets and rules; that is, it performs a recursive traversal of any rulelist associated with it. For every rule in the rulelist, the same logic is applied (only the logic for regex-based rules is described; that for sprintf-based rules is very similar):
-
The input for the rule is the resource URL as received from the HTTP header, i.e., the portion of the URL from the first '/' after the host:port fields to the end of the URL.
-
The input is normalized.
-
The input is matched against the rule's regex. If the match fails, the rule is not applied and the next rule is tried. If the match succeeds, the result is a vector of values.
-
If the URL contains a query string, the names and values of the parameters are decoded by split_and_decode().
-
The names and values of any parameters in the request body are also decoded.
-
The destination URL is composed
-
The value of each parameter in the destination URL is taken from (in order of priority)
-
The value of a parameter in the match result;
-
The value of a named parameter in the query string of the input nice URL;
-
If the original request was submitted by the POST method, the value of a named parameter in the body of the POST request; or
-
if a parameter value cannot be derived from one of these sources, the rule is not applied and the next rule is tried.
The path translation function described above is internal to the Web server, so its signature is not appropriate for Virtuoso/PL calls and thus is not published. Virtuoso/PL developers can harness the same functionality using the DB.DBA.URLREWRITE_APPLY API call.
Enabling URL Rewriting via the Virtuoso Conductor UI
Virtuoso is a full-blown HTTP server in its own right. The HTTP server functionality co-exists with the product core (i.e., DBMS Engine, Web Services Platform, WebDAV filesystem, and other components of the Universal Server). As a result, it has the ability to multi-home Web domains within a single instance across a variety of domain name and port combinations. In addition, it also enables the creation of multiple virtual directories per domain.
In addition to the basic functionality, Virtuoso facilitates the association of URL Rewriting rules with the virtual directories associated with a hosted Web domain.
In all cases, Virtuoso enables you to configure virtual domains, virtual directories and URL rewrite rules for one or more virtual directories, via the (X)HTML-based Conductor Admin User Interface or a collection of Virtuoso Stored Procedure Language (PL)-based APIs.
The steps for configuring URL Rewrite rules via the Virtuoso Conductor are as follows:
-
Assuming you are using the local demonstration database, load http://example.com/conductor into your browser, and then proceed through the Conductor as follows:
-
Click the "Web Application Server", and "Virtual Domains & Directories" tabs
-
Pick the domain that contains the virtual directories to which the rules are to be applied (in this case the default was taken)
-
Click on the "URL-rewrite" link to create, delete, or edit a rule as shown below:
-
Create a Rule for HTML Representation Requests (via SPARQL SELECT Query)
-
Create a Rule for RDF Representation Requests (via SPARQL CONSTRUCT Query)
-
Then save and exit the Conductor, and test your rules with curl or any other User Agent.
Figure 16.184. URL-rewrite UI using Conductor
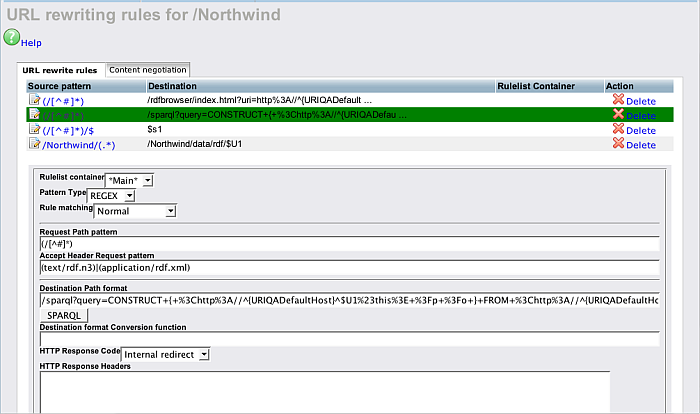
Enabling URL Rewriting via Virtuoso PL
The vhost_define()API is used to define virtual hosts and virtual paths hosted by the Virtuoso HTTP server. URL rewriting is enabled through this function's opts parameter. opts is of type ANY, e.g., a vector of field-value pairs. Numerous fields are recognized for controlling different options. The field value url_rewrite controls URL rewriting. The corresponding field value is the IRI of a rule list to apply.
Configuration API
Virtuoso includes the following functions for managing URL rewriting rules and rule lists. The names are self-explanatory.
-- Deletes a rewriting rule DB.DBA.URLREWRITE_DROP_RULE -- Creates a rewriting rule which uses sprintf-based pattern matching DB.DBA.URLREWRITE_CREATE_SPRINTF_RULE -- Creates a rewriting rule which uses regular expression (regex) based pattern matching DB.DBA.URLREWRITE_CREATE_REGEX_RULE -- Deletes a rewriting rule list DB.DBA.URLREWRITE_DROP_RULELIST -- Creates a rewriting rule list DB.DBA.URLREWRITE_CREATE_RULELIST -- Lists all the rules whose IRI match the specified 'SQL like' pattern DB.DBA.URLREWRITE_ENUMERATE_RULES -- Lists all the rule lists whose IRIs match the specified 'SQL like' pattern DB.DBA.URLREWRITE_ENUMERATE_RULELISTS
Creating Rewriting Rules
Rewriting rules take two forms: sprintf-based or regex-based. When used for nice URL to long URL conversion, the only difference between them is the syntax of format strings. The reverse long to nice conversion works only for sprintf-based rules, whereas regex-based rules are unidirectional.
For the purposes of describing how to make dereferenceable URIs for linked data, we will stick with the nice to long conversion using regex-based rules.
Regex rules are created using the URLREWRITE_CREATE_REGEX_RULE() function.
Example - URL Rewriting For the Northwind Linked Data View
The Northwind schema is comprised of commonly understood SQL Tables that include: Customers, Orders, Employees, Products, Product Categories, Shippers, Countries, Provinces etc.
An Linked Data View of SQL data is an RDF named graph (RDF data set) comprised of RDF Linked Data (triples) stored in a Virtuoso Quad Store (the native RDF Data Management realm of Virtuoso).
In this example we are going interact with Linked Data deployed into the Data-Web from a live instance of Virtuoso, which uses the URL Rewrite rules from the prior section.
The components used in the example are as follows:
-
Virtuoso SPARQL Endpoint: http://demo.openlinksw.com/sparql
-
Named RDF Graph: http://demo.openlinksw.com/Northwind
-
Entity ID - http://demo.openlinksw.com/Northwind/Customer/ALFKI#this
-
Information Resource: http://demo.openlinksw.com/Northwind/Customer/ALFKI
-
Interactive SPARQL Query Builder (iSPARQL) - http://demo.openlinksw.com/DAV/JS/isparql/index.html
Northwind URL Rewriting Verification Using curl
The curl utility provides a useful tool for verifying HTTP server responses and rewriting rules. The curl exchanges below show the URL rewriting rules defined for the Northwind RDF view being applied.
Example 1:
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI HTTP/1.1 303 See Other Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5 Connection: close Content-Type: text/html; charset=ISO-8859-1 Date: Tue, 14 Aug 2007 13:30:02 GMT Accept-Ranges: bytes Location: http://demo.openlinksw.com/about/html/http/demo.openlinksw.com/Northwind/Customer/ALFKI Content-Length: 0
Example 2:
$ curl -I -H "Accept: application/rdf+xml" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 303 See Other
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Tue, 14 Aug 2007 13:30:22 GMT
Accept-Ranges: bytes
Location: /sparql?query=CONSTRUCT+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}+FROM+%3Chttp%3A//demo.openlinksw.com/Northwind%3E+WHERE+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}&format=application/rdf%2Bxml
Content-Length: 0
Example 3:
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI#this HTTP/1.1 404 Not Found Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5 Connection: Keep-Alive Content-Type: text/html; charset=ISO-8859-1 Date: Tue, 14 Aug 2007 13:31:01 GMT Accept-Ranges: bytes Content-Length: 0
The output above shows how RDF entities from the Data-Web, in this case customer ALFKI, are exposed in the Document Web. The power of SPARQL coupled with URL rewriting enables us to produce results in line with the desired representation. A SPARQL SELECT or CONSTRUCT query is used depending on whether the requested representation is text/html or application/rdf+xml, respectively.
The 404 response in Example 3 indicates that no HTML representation is available for entity ALFKI#this. In most cases, a URI of this form (containing a '#' fragment identifier) will not reach the server. This example supposes that it does: i.e., the RDF client and network routing allows the suffixed request. The presence of the #this suffix implicitly states that this is a request for a data resource in the Data-Web realm, not a document resource from the Document Web.2
Rather than return 404, we could instead choose to construct our rewriting rules to perform a 303 redirect, so that the response for ALFKI#this in Example 3 becomes the same as that for ALFKI in Example 1.
Transparent Content Negotiation
So as not to overload our preceding description of Linked Data deployment with excessive detail, the description of content negotiation presented thus far was kept deliberately brief. This section discusses content negotiation in more detail.
HTTP/1.1 Content Negotiation
Recall that a resource (conceptual entity) identified by a URI may be associated with more than one representation (e.g. multiple languages, data formats, sizes, resolutions). If multiple representations are available, the resource is referred to as negotiable and each of its representations is termed a variant. For instance, a Web document resource, named 'ALFKI' may have three variants: alfki.xml, alfki.html and alfki.txt all representing the same data. Content negotiation provides a mechanism for selecting the best variant.
As outlined in the earlier brief discussion of content negotiation, when a user agent requests a resource, it can include with the request Accept headers (Accept, Accept-Language, Accept-Charset, Accept-Encoding etc.) which express the user preferences and user agent capabilities. The server then chooses and returns the best variant based on the Accept headers. Because the selection of the best resource representation is made by the server, this scheme is classed as server-driven negotiation.
Transparent Content Negotiation
An alternative content negotiation mechanism is Transparent Content Negotiation (TCN), a protocol defined by RFC2295 . TCN offers a number of benefits over standard HTTP/1.1 negotiation, for suitably enabled user agents.
RFC2295 introduces a number of new HTTP headers including the Negotiate request header, and the TCN and Alternates response headers. (Krishnamurthy et al. note that although the HTTP/1.1 specification reserved the Alternates header for use in agent driven negotiation, it was not fully specified. Consequently under a pure HTTP/1.1 implementation as defined by RFC2616, server-driven content negotiation is the only option. RFC2295 addresses this issue.)
Deficiencies of HTTP/1.1 Server-Driven Negotiation
Weaknesses of server-driven negotiation highlighted by RFCs 2295 and 2616 include:
-
Inefficiency - Sending details of a user agent's capabilities and preferences with every request is very inefficient, not least because very few Web resources have multiple variants, and expensive in terms of the number of Accept headers required to fully describe all but the most simple browser's capabilities.
-
Server doesn't always know 'best' - Having the server decide on the 'best' variant may not always result in the most suitable resource representation being returned to the client. The user agent might often be better placed to decide what is best for its needs.
Variant Selection By User Agent
Rather than rely on server-driven negotiation and variant selection by the server, a user agent can take full control over deciding the best variant by explicitly requesting transparent content negotiation through the Negotiate request header. The negotiation is 'transparent' because it makes all the variants on the server visible to the agent.
Under this scheme, the server sends the user agent a list, represented in an Alternates header, containing the available variants and their properties. The user agent can then choose the best variant itself. Consequently, the agent no longer needs to send large Accept headers describing in detail its capabilities and preferences. (However, unless caching is used, user-agent driven negotiation does suffer from the disadvantage of needing a second request to obtain the best representation. By sending its best guess as the first response, server driven negotiation avoids this second request if the initial best guess is acceptable.)
Variant Selection By Server
As well as variant selection by the user agent, TCN allows the server to choose on behalf of the user agent if the user agent explicitly allows it through the Negotiate request header. This option allows the user agent to send smaller Accept headers containing enough information to allow the server to choose the best variant and return it directly. The server's choice is controlled by a 'remote variant selection algorithm' as defined in RFC2296.
Variant Selection By End-User
A further option is to allow the end-user to select a variant, in case the choice made by negotiation process is not optimal. For instance, the user agent could display an HTML-based 'pick list' of variants constructed from the variant list returned by the server. Alternatively the server could generate this pick list itself and include it in the response to a user agent's request for a variant list. (Virtuoso currently responds this way.)
Transparent Content Negotiation in Virtuoso HTTP Server
The following section describes the Virtuoso HTTP server's TCN implementation which is based on RFC2295, but without "Feature" negotiation. OpenLink's RDF rich clients, iSparql and the OpenLink RDF Browser, both support TCN. User agents which do not support transparent content negotiation continue to be handled using HTTP/1.1 style content negotiation (whereby server-side selection is the only option - the server selects the best variant and returns a list of variants in an Alternates response header).
Describing Resource Variants
In order to negotiate a resource, the server needs to be given information about each of the variants. Variant descriptions are held in SQL table HTTP_VARIANT_MAP. The descriptions themselves can be created, updated or deleted using Virtuoso/PL or through the Conductor UI. The table definition is as follows:
create table DB.DBA.HTTP_VARIANT_MAP ( VM_ID integer identity, -- unique ID VM_RULELIST varchar, -- HTTP rule list name VM_URI varchar, -- name of requested resource e.g. 'page' VM_VARIANT_URI varchar, -- name of variant e.g. 'page.xml', 'page.de.html' etc. VM_QS float, -- Source quality, a number in the range 0.001-1.000, with 3 digit precision VM_TYPE varchar, -- Content type of the variant e.g. text/xml VM_LANG varchar, -- Content language e.g. 'en', 'de' etc. VM_ENC varchar, -- Content encoding e.g. 'utf-8', 'ISO-8892' etc. VM_DESCRIPTION long varchar, -- a human readable description about the variant e.g. 'Profile in RDF format' VM_ALGO int default 0, -- reserved for future use primary key (VM_RULELIST, VM_URI, VM_VARIANT_URI) ) create unique index HTTP_VARIANT_MAP_ID on DB.DBA.HTTP_VARIANT_MAP (VM_ID)
Configuration using Virtuoso/PL
Two functions are provided for adding or updating, or removing variant descriptions using Virtuoso/PL:
-- Adding or Updating a Resource Variant: DB.DBA.HTTP_VARIANT_ADD ( in rulelist_uri varchar, -- HTTP rule list name in uri varchar, -- Requested resource name e.g. 'page' in variant_uri varchar, -- Variant name e.g. 'page.xml', 'page.de.html' etc. in mime varchar, -- Content type of the variant e.g. text/xml in qs float := 1.0, -- Source quality, a floating point number with 3 digit precision in 0.001-1.000 range in description varchar := null, -- a human readable description of the variant e.g. 'Profile in RDF format' in lang varchar := null, -- Content language e.g. 'en', 'bg'. 'de' etc. in enc varchar := null -- Content encoding e.g. 'utf-8', 'ISO-8892' etc. ) --Removing a Resource Variant DB.DBA.HTTP_VARIANT_REMOVE ( in rulelist_uri varchar, -- HTTP rule list name in uri varchar, -- Name of requested resource e.g. 'page' in variant_uri varchar := '%' -- Variant name filter )
Configuration using Conductor UI
The Conductor 'Content negotiation' panel for describing resource variants and configuring content negotiation is depicted below. It can be reached by selecting the 'Virtual Domains & Directories' tab under the 'Web Application Server' menu item, then selecting the 'URL rewrite' option for a logical path listed amongst those for the relevant HTTP host, e.g. '{Default Web Site}'
The input fields reflect the supported 'dimensions' of negotiation which include content type, language and encoding. Quality values corresponding to the options for 'Source Quality' are as follows:
Table 16.18. Source Quality
| Source Quality | Quality Value |
|---|---|
| perfect representation | 1.000 |
| threshold of noticeable loss of quality | 0.900 |
| noticeable, but acceptable quality reduction | 0.800 |
| barely acceptable quality | 0.500 |
| severely degraded quality | 0.300 |
| completely degraded quality | 0.000 |
Variant Selection Algorithm
When a user agent instructs the server to select the best variant, Virtuoso does so using the selection algorithm below:
If a virtual directory has URL rewriting enabled (has the 'url_rewrite' option set), the web server:
-
Looks in DB.DBA.HTTP_VARIANT_MAP for a VM_RULELIST matching the one specified in the 'url_rewrite' option
-
If present, it loops over all variants for which VM_URI is equal to the resource requested
-
For every variant it calculates the source quality based on the value of VM_QS and the source quality given by the user agent
-
If the best variant is found, it adds TCN HTTP headers to the response and passes the VM_VARIANT_URI to the URL rewriter
-
If the user agent has asked for a variant list, it composes such a list and returns an 'Alternates' HTTP header with response code 300
-
If no URL rewriter rules exist for the target URL, the web server returns the content of the dereferenced VM_VARIANT_URI.
The server may return the best-choice resource representation or a list of available resource variants. When a user agent requests transparent negotiation, the web server returns the TCN header "choice". When a user agent asks for a variant list, the server returns the TCN header "list".
Examples
In this example we assume the following files have been uploaded to the Virtuoso WebDAV server, with each containing the same information but in different formats:
-
/DAV/TCN/page.xml - a XML variant
-
/DAV/TCN/page.html - a HTML variant
-
/DAV/TCN/page.txt - a text variant
We add TCN rules and define a virtual directory:
DB.DBA.HTTP_VARIANT_ADD ('http_rule_list_1', 'page', 'page.html','text/html', 0.900000, 'HTML variant');
DB.DBA.HTTP_VARIANT_ADD ('http_rule_list_1', 'page', 'page.txt', 'text/plain', 0.500000, 'Text document');
DB.DBA.HTTP_VARIANT_ADD ('http_rule_list_1', 'page', 'page.xml', 'text/xml', 1.000000, 'XML variant');
DB.DBA.VHOST_DEFINE (lpath=>'/DAV/TCN/',
ppath=>'/DAV/TCN/',
is_dav=>1,
vsp_user=>'dba',
opts=>vector ('url_rewrite', 'http_rule_list_1'));
Having done this we can now test the setup with a suitable HTTP client, in this case the curl command line utility. In the following examples, the curl client supplies Negotiate request headers containing content negotiation directives which include:
-
"trans" - The user agent supports transparent content negotiation for the current request.
-
"vlist" - The user agent requests that any transparently negotiated response for the current request includes an Alternates header with the variant list bound to the negotiable resource. Implies "trans".
-
"*" - The user agent allows servers and proxies to run any remote variant selection algorithm.
The server returns a TCN response header signalling that the resource is transparently negotiated and either a choice or a list response as appropriate.
In the first curl exchange, the user agent indicates to the server that, of the formats it recognizes, HTML is preferred and it instructs the server to perform transparent content negotiation. In the response, the Vary header field expresses the parameters the server used to select a representation, i.e. only the Negotiate and Accept header fields are considered.
$ curl -i -H "Accept: text/xml;q=0.3,text/html;q=1.0,text/plain;q=0.5,*/*; q=0.3" -H "Negotiate: *" http://example.com/DAV/TCN/page HTTP/1.1 200 OK Server: Virtuoso/05.00.3021 (Linux) i686-pc-linux-gnu VDB Connection: Keep-Alive Date: Wed, 31 Oct 2007 15:43:18 GMT Accept-Ranges: bytes TCN: choice Vary: negotiate,accept Content-Location: page.html Content-Type: text/html ETag: "14056a25c066a6e0a6e65889754a0602" Content-Length: 49 <html> <body> some html </body> </html>
Next, the source quality values are adjusted so that the user agent indicates that XML is its preferred format.
$ curl -i -H "Accept: text/xml,text/html;q=0.7,text/plain;q=0.5,*/*;q=0.3" -H "Negotiate: *" http://example.com/DAV/TCN/page HTTP/1.1 200 OK Server: Virtuoso/05.00.3021 (Linux) i686-pc-linux-gnu VDB Connection: Keep-Alive Date: Wed, 31 Oct 2007 15:44:07 GMT Accept-Ranges: bytes TCN: choice Vary: negotiate,accept Content-Location: page.xml Content-Type: text/xml ETag: "8b09f4b8e358fcb7fd1f0f8fa918973a" Content-Length: 39 <?xml version="1.0" ?> <a>some xml</a>
In the final example, the user agent wants to decide itself which is the most suitable representation, so it asks for a list of variants. The server provides the list, in the form of an Alternates response header, and, in addition, sends an HTML representation of the list so that the end user can decide on the preferred variant himself if the user agent is unable to.
$ curl -i -H "Accept: text/xml,text/html;q=0.7,text/plain;q=0.5,*/*;q=0.3" -H "Negotiate:
vlist" http://example.com/DAV/TCN/page HTTP/1.1 300 Multiple Choices Server:
Virtuoso/05.00.3021 (Linux) i686-pc-linux-gnu VDB Connection: close Content-Type:
text/html; charset=ISO-8859-1 Date: Wed, 31 Oct 2007 15:44:35 GMT Accept-Ranges:
bytes TCN: list Vary: negotiate,accept Alternates: {"page.html" 0.900000 {type text/html}},
{"page.txt" 0.500000 {type text/plain}}, {"page.xml" 1.000000 {type text/xml}} Content-Length: 368
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html>
<head>
<title>300 Multiple Choices</title>
</head>
<body>
<h1>Multiple Choices</h1>
Available variants:
<ul>
<li>
<a href="page.html">HTML variant</a>, type text/html</li>
<li><a href="page.txt">Text document</a>, type text/plain</li>
<li><a href="page.xml">XML variant</a>, type text/xml</li>
</ul>
</body>
</html>