6.2.3. Web Services
Content Crawler
Some of the supported features are:
-
Import Targets : Virtuoso can be set up to retrieve content from external web sites and host it in its own WebDAV repository via this page.
Figure 6.13. Web Robot - Crawl Job
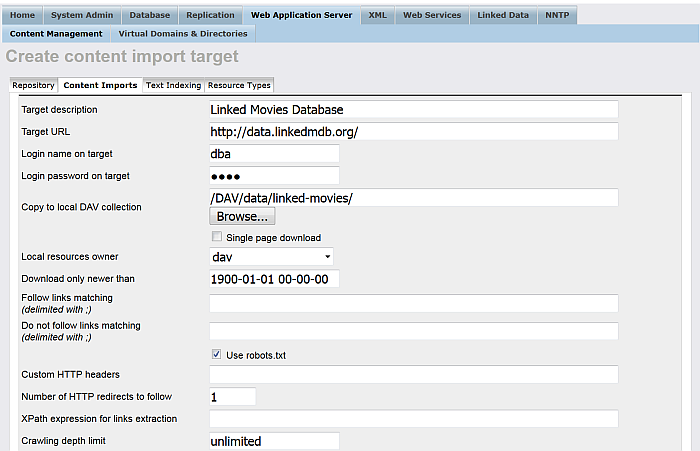
Figure 6.14. Web Robot - Crawl Job
-
Target description lets you provide a friendly name for the target that you are defining.
-
Target URL is the url of the web site that you are trying to retrieve content from. Only the hostname should be provided here, along with the protocol. For example http://www.myhost.com.
-
Login name on target is the username for accessing the remote server, if required.
-
Login password on target is the password for the login name above.
-
Copy to local DAV collection this *mandatory* value will serve as the DAV root location if content is stored locally.
-
Single page download radio button specifies whether Virtuoso will retrieved linked content also.
-
Local Resources Owner The DAV user that will be the owner of the content that will copied to DAV.
-
The Download only newer than field allows you to specify a datetime value to prevent Virtuoso downloading files that are older than that datetime.
-
Use the Follow links matching (delimited with ;) field to limit the content that is downloaded by specify pattern matching criteria.
-
Do not follow links matching (delimited with ;) allows you limit content by specifying what files not to download.
-
-
Use robots.txt check-box is checked by default.
-
Custom HTTP headers can be used to specigy custom HTTP headers.
-
Number of HTTP redirects to follow is set by default to 1.
-
XPath expression for links extraction allows to be entered custom XPath expression.
-
Crawling depth limit allows to limit crawling depth. By default is set to "unlimited".
-
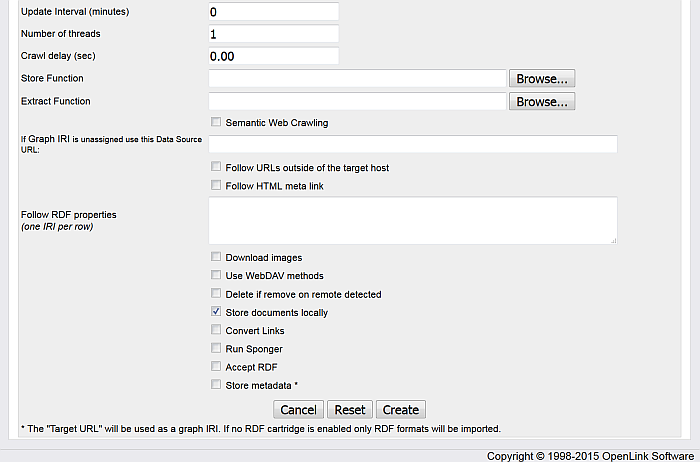
Update Interval (minutes) is on what interval the updated of the crawled data should be performed.
-
Number of threads allows setting crawling threads.
-
Crawl delay (sec) allows to be specified a delay. By default is set to "0.00".
-
Store Function allows to be used a specific stored function for ex. in Semantic Sitemaps crawling.
![[Tip]](images/tip.png)
See Also: -
Extract Function allows to be used a specific extract function for ex. in Semantic Sitemaps crawling. If left empty, will be used a system Store function.
See Also: -
Semantic Web Crawling : hatch to retrieve Semantic Sitemaps. If left empty, will be used a system Store function.
-
If Graph IRI is unassigned use this Data Source URL: use to specify a custom graph URI for data storage.
-
Follow URLs outside of the target host is check-box to specify either to follow URIS outside of the target host.
-
Follow HTML meta link is check-box to specifiy either to follow HTML meta links.
-
Follow RDF properties (one IRI per row) .
-
Download Images radio buttons to allow Virtuoso to pull down image type also. You may want to prevent this if you are more interested in the textual content rather than bandwidth draining images.
-
Use WebDAV methods can be checked if the host is known to support WebDAV methods. This would enable better copying of sites that support DAV.
-
Delete if remove on remote detected can be switched on so that when Virtuoso synchronizes its content with that on the remote host it will check for files that have been removed on the remote and remove them from the local copy also.
-
Store metadata* when checked offers to be stored respectively metadata from FOAF, RDF, RSS/RDF and GRDLL data depending on which check-box is checked.
-
When all details have been completed press the Add (or Update if updating) button to submit the web robot task to the queue.
-
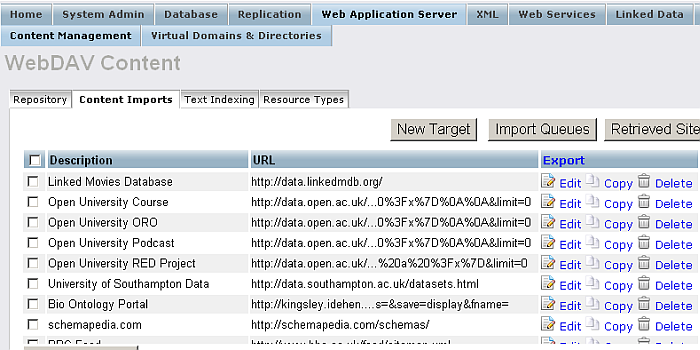
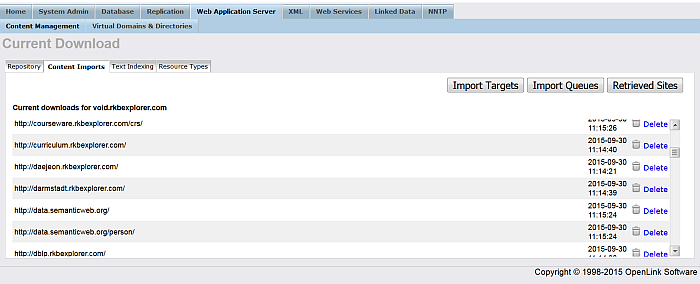
Import Queues : This page shows you a list of web copy targets that have been enlisted with the Virtuoso Server, and a list of web robot update schedules. Several options are available for each item listed: Start, Update, Schedule, Reset, and Stop. You can configure the scheduled update interval by pressing the Schedule link and entering a value in minutes. Once that is done you can start the schedule by pressing the Start link. You make a manual update of the content by pressing the Update link. You can stop the scheduled updates taking place by pressing the Stop link. To reset the details of the web copy item press the Reset link.
Figure 6.15. Web Robot - Queues
-
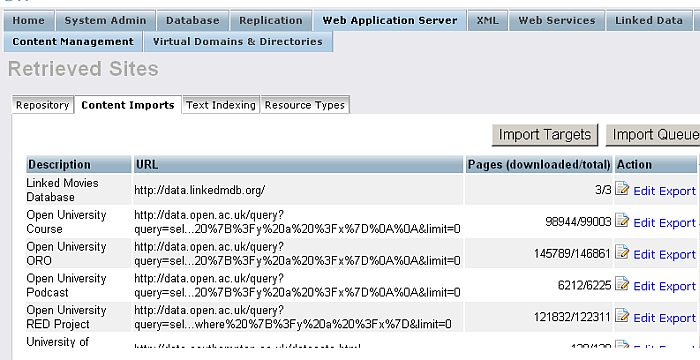
Retrieved Sites : You can view a list of the links retrieved from the web copy from this page. You are also able to remove some of the content from this page by following the Edit link.
Figure 6.16. Web Robot - Retrieved Links
-
Export : You can export content from the WebDAV repository. Note that you can only export content that has been retrieved using Virtuoso's Web Robot.
When you click the "Export" link for a retrieved collection, you will be presented with a form for selecting the export target location. Choose the export method: either File System or DAV by clicking the "External WebDAV Server URL" check-box. This lets you indicate to the remote target where to store the exported content. Then type the target URL to an existing location on the server. Finally press the Export button to export. A confirmation will be supplied once the operation is complete.
Figure 6.17. Web Robot - Exporting Content
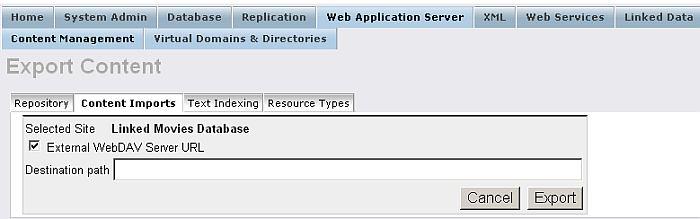
![[Note]](images/note.png)
Note: If is not checked the "External WebDAV Server URL" check-box, i.e. you are selecting the filesystem method, then you are restricted to Virtuoso targets. However WebDAV methods can be applied to any WebDAV server. WebDAV methods assume that the target is publicly available for writing.
-
Populate the RDF Quad Store : Virtuoso's built-in Content Crawler to can be used to populate its RDF Quad Store, as a one-time run or on a scheduled basis.
Transforming data sources into RDF "on the fly" is sufficient for many use cases, but there are times when the volume or sheer nature of a data source makes batch-loading necessary.
For example, Freebase offers RDF representations of its data, but it doesn't publish RDF dumps; even if it did, such dumps would usually be outdated by the time they were loaded.
One practical solution takes the form of a scheduled crawl of specific resources of interest.
Set Up the Content Crawler to Gather RDF
The Virtuoso Conductor can be used to set up various Content Crawler Jobs:
Setting up a Content Crawler Job to Add RDF Data to the Quad Store
See details how to use Virtuoso Crawler for including the Sponger options so you crawl non-RDF but get RDF and this to the Quad Store.
Setting up a Content Crawler Job to Retrieve Sitemaps (when the source includes RDFa)
The following section describes how to set up a crawler job for getting content of a basic Sitemap where the source includes RDFa.
-
From the Virtuoso Conductor User Interface i.e. http://cname:port/conductor, login as the "dba" user.
-
Go to the "Web Application Server" tab.
Figure 6.18. Setting up a Content Crawler Job to Retrieve Sitemaps
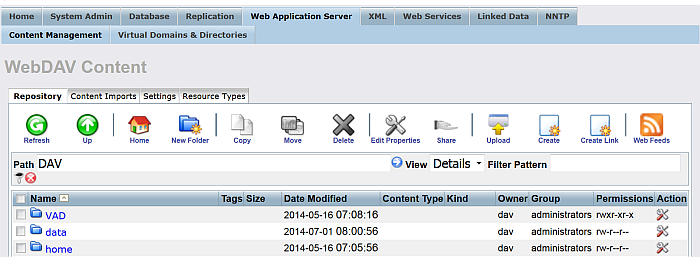
-
Go to the "Content Imports" tab.
Figure 6.19. Setting up a Content Crawler Job to Retrieve Sitemaps
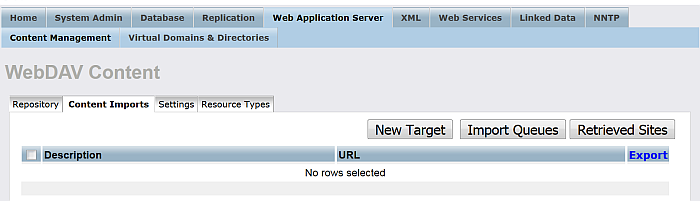
-
Click on the "New Target" button.
Figure 6.20. Setting up a Content Crawler Job to Retrieve Sitemaps
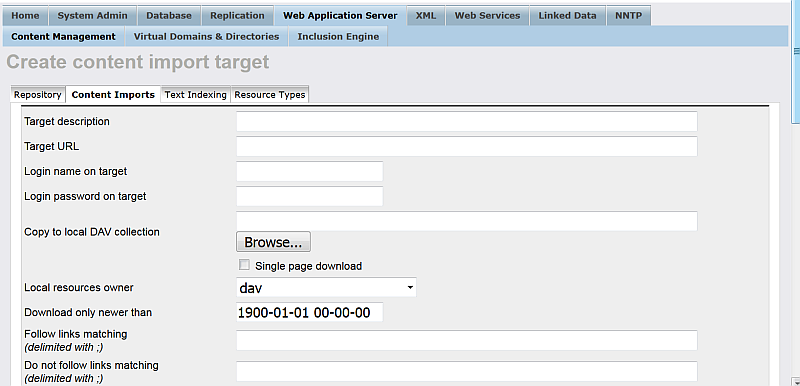
-
In the form displayed:
-
Enter a name of choice in the "Target description" text box:
Virtuoso Sample Example
-
Enter the URL of the site to be crawled in the "Target URL" text box:
http://virtuoso.openlinksw.com/sitemap.xml
-
Enter the location in the Virtuoso WebDAV repository the crawled should stored, in the "Copy to local DAV collection" text box, for example, if user demo is available, then:
/DAV/home/demo/VirtSample/
-
Choose the "Local resources owner" for the collection from the list box available, for ex: user demo.
-
Select the "Accept RDF" check box.
-
Optionally you can select "Convert Links" to make all HREFs in the local stored content relative.
Figure 6.21. Setting up a Content Crawler Job to Retrieve Sitemaps
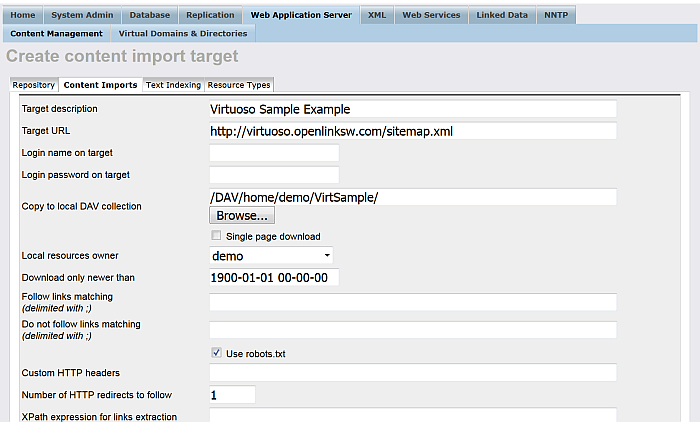
Figure 6.22. Setting up a Content Crawler Job to Retrieve Sitemaps
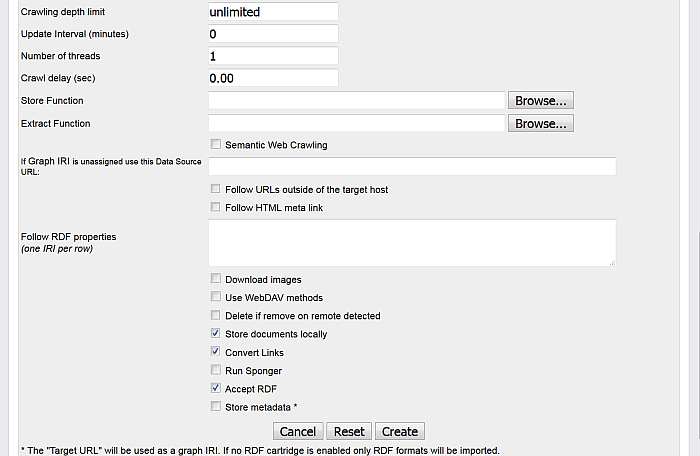
-
-
Click the "Create" button to create the import.
Figure 6.23. Setting up a Content Crawler Job to Retrieve Sitemaps
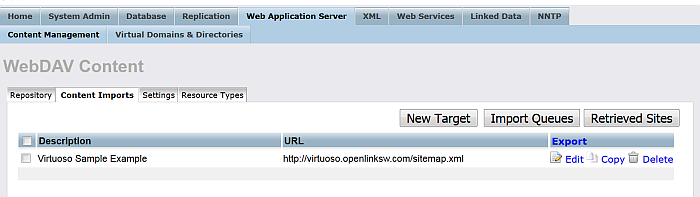
-
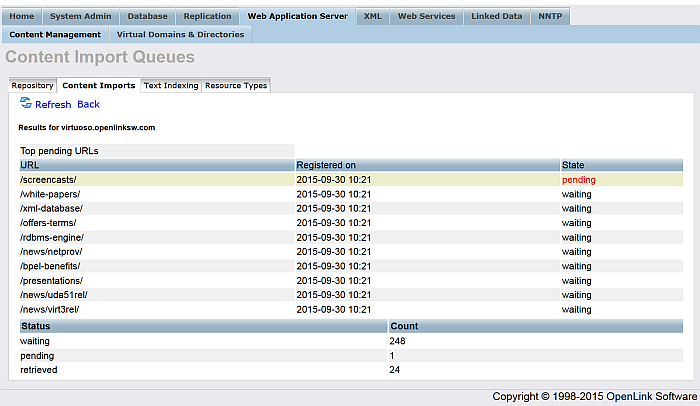
Click the "Import Queues" button.
Figure 6.24. Setting up a Content Crawler Job to Retrieve Sitemaps
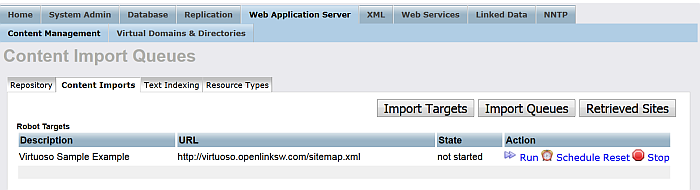
-
For the "Robot targets" with label "Virtuoso Sample Example" click the "Run" button.
-
This will result in the Target site being crawled and the retrieved pages stored locally in DAV and any network resource triples being fetched in the RDF Quad store.
Figure 6.25. Setting up a Content Crawler Job to Retrieve Sitemaps
-
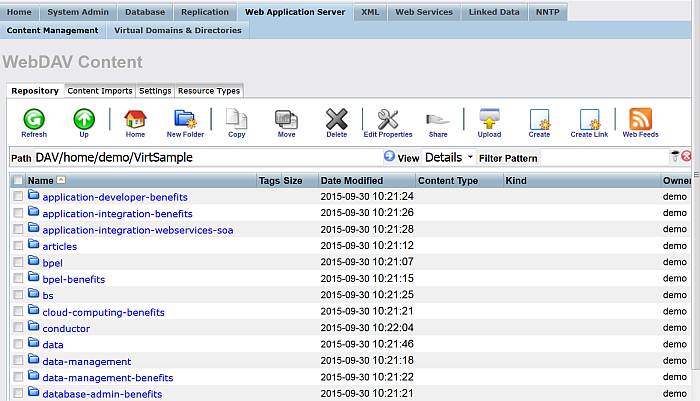
Go to the "Web Application Server" -> "Content Management" tab and navigate to the location of newly created DAV collection:
/DAV/home/demo/VirtSample/
-
The retrieved content will be shown:
Figure 6.26. Setting up a Content Crawler Job to Retrieve Sitemaps
Setting up a Content Crawler Job to Retrieve Semantic Sitemaps (a variation of the standard sitemap)
The following section describes how to set up crawler job for getting Semantic Sitemap's content: a variation of standard sitemap:
-
From the Virtuoso Conductor User Interface i.e. http://cname:port/conductor, login as the "dba" user.
-
Go to "Web Application Server".
Figure 6.27. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
-
Go to "Content Imports".
Figure 6.28. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
-
Click "New Target".
Figure 6.29. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
-
In the shown form:
-
Enter for "Target description":
Semantic Web Sitemap Example
-
Enter for "Target URL":
http://virtuoso.openlinksw.com/sitemap-semantic.xml
-
Enter the location in the Virtuoso WebDAV repository the crawled should stored in the "Copy to local DAV collection" text box, for example, if user demo is available, then:
/DAV/home/demo/semantic_sitemap/
-
Choose the "Local resources owner" for the collection from the list box available, for ex: user demo.
-
Hatch "Semantic Web Crawling"
-
Note: when you select this option, you can either:
-
Leave the Store Function and Extract Function empty - in this case the system Store and Extract functions will be used for the Semantic Web Crawling Process, or:
-
You can select your own Store and Extract Functions, for ex:
-- Example of Extract Function use WS; create procedure WS.WS.SITEMAP_BB_PARSE ( in _host varchar, in _url varchar, in _root varchar, inout _content varchar, in _c_type varchar := null, in lev int := 0)) { --pl_debug+ declare xt, xp, graph any; declare inx int; -- dbg_obj_print ('WS.WS.GET_URLS_SITEMAP', _url); declare exit handler for sqlstate '*' { -- dbg_obj_print (__SQL_MESSAGE); return; }; if (_url like '%.xml.gz') { _content := gzip_uncompress (_content); } if (_url like '%.xml' or _url like '%.xml.gz' or _url like '%.rdf') { xt := xtree_doc (_content); if (xpath_eval ('/urlset/dataset', xt) is not null) { xp := xpath_eval ('/urlset/dataset/dataDumpLocation/text()', xt, 0); graph := cast (xpath_eval ('/urlset/dataset/datasetURI/text()', xt) as varchar); if (length (graph)) update VFS_SITE set VS_UDATA = serialize (vector ('graph', graph)) where VS_HOST = _host and VS_ROOT = _root; inx := 0; foreach (any u in xp) do { declare hf, host, url varchar; u := cast (u as varchar); hf := WS.WS.PARSE_URI (u); host := hf[1]; --dbg_obj_print ('WS.WS.GET_URLS_SITEMAP PARSE', u); url := hf[2]; insert soft VFS_QUEUE (VQ_HOST, VQ_TS, VQ_URL, VQ_STAT, VQ_ROOT, VQ_OTHER) values (host, now (), url, 'waiting', _root, NULL); if (row_count () = 0) update VFS_QUEUE set VQ_STAT = 'waiting', VQ_TS = now () where VQ_HOST = host and VQ_ROOT = _root and VQ_URL = url; inx := inx + 1; } } if (xpath_eval ('/sitemapindex/sitemap/loc', xt) is not null) { xp := xpath_eval ('/sitemapindex/sitemap/loc/text()', xt, 0); inx := 0; foreach (any u in xp) do { declare hf, host, url varchar; u := trim (cast (u as varchar)); hf := WS.WS.PARSE_URI (u); host := hf[1]; -- dbg_obj_print ('WS.WS.GET_URLS_SITEMAP', host, _host); url := hf[2]; if (url <> '') { insert soft VFS_QUEUE (VQ_HOST, VQ_TS, VQ_URL, VQ_STAT, VQ_ROOT, VQ_OTHER) values (host, now (), url, 'waiting', _root, NULL); if (row_count () = 0) update VFS_QUEUE set VQ_STAT = 'waiting', VQ_TS = now () where VQ_HOST = host and VQ_ROOT = _root and VQ_URL = url; inx := inx + 1; } } } } commit work; } ; -- Example of Store Function use WS; create procedure WS.WS.SITEMAP_BB_STORE ( in _host varchar, in _url varchar, in _root varchar, inout _content varchar, in _s_etag varchar, in _c_type varchar, in store_flag int := 1, in udata any := null, in lev int := 0) { --pl_debug+ declare graph varchar; -- dbg_obj_print ('WS.WS.SITEMAP_BB_STORE', _url, udata); if (isarray (udata)) graph := get_keyword ('graph', udata); else graph := null; if (graph is not null and _url like '%.rdf') { DB.DBA.RDF_LOAD_RDFXML (_content, graph, graph); DB.DBA.VT_INC_INDEX_DB_DBA_RDF_OBJ (); } insert soft VFS_URL (VU_HOST, VU_URL, VU_CHKSUM, VU_CPTIME, VU_ETAG, VU_ROOT) values (_host, _url, md5 (_content), now (), _s_etag, _root); if (row_count () = 0) update VFS_URL set VU_CHKSUM = md5 (_content), VU_CPTIME = now (), VU_ETAG = _s_etag where VU_HOST = _host and VU_URL = _url and VU_ROOT = _root; commit work; } ;
-
-
-
-
Optionally you can select "Convert Link" to make all HREFs in the local stored content relative.
-
Hatch "Accept RDF"
Figure 6.30. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
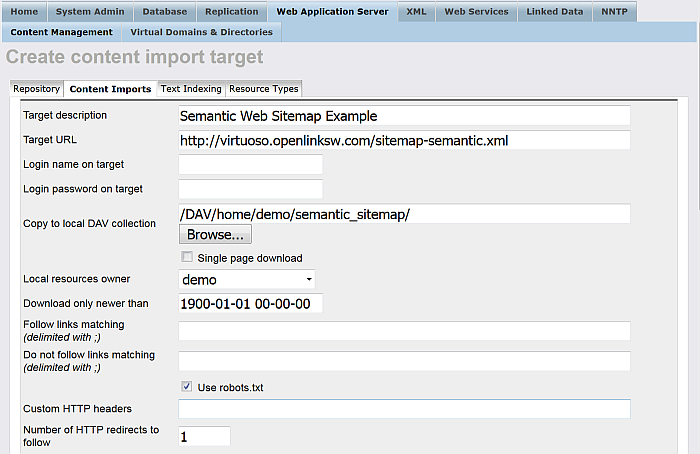
Figure 6.31. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
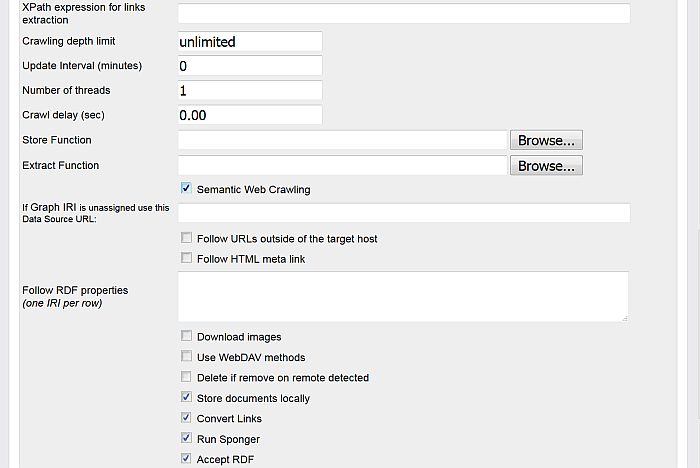
Figure 6.32. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content

-
Optionally you can hatch "Store metadata *" and specify which RDF Cartridges to be included from the Sponger:
Figure 6.33. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
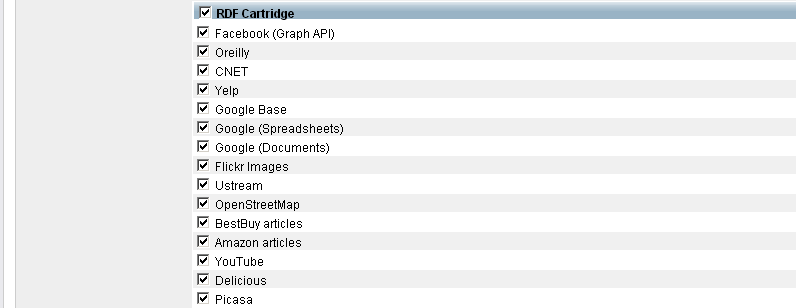
-
Click the button "Create".
Figure 6.34. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
-
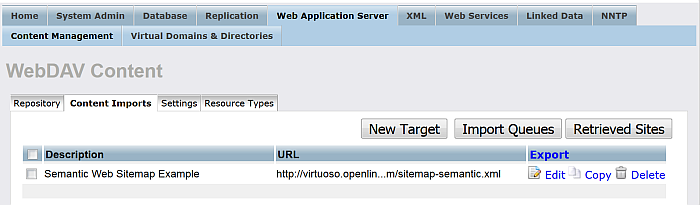
Click "Import Queues".
Figure 6.35. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
-
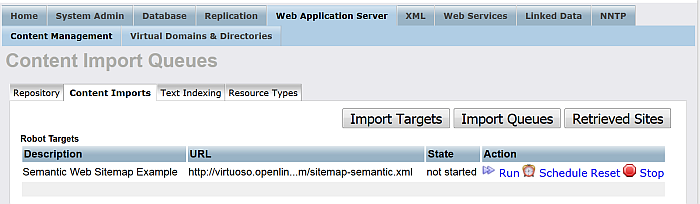
For "Robot target" with label "Semantic Web Sitemap Example" click "Run".
-
As result should be shown the number of the pages retrieved.
Figure 6.36. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
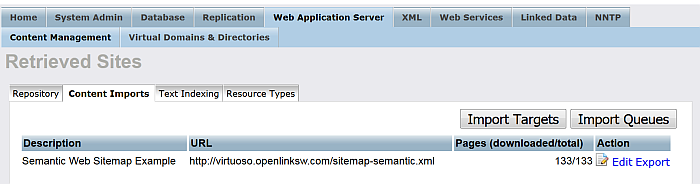
-
Check the retrieved RDF data from your Virtuoso instance sparql endpoint http://cname:port/sparql with the following query selecting all the retrieved graphs for ex:
SELECT ?g FROM <http://host:port/> WHERE { graph ?g { ?s ?p ?o } . FILTER ( ?g LIKE <http://virtuoso.openlinksw.com/%> ) }Figure 6.37. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content
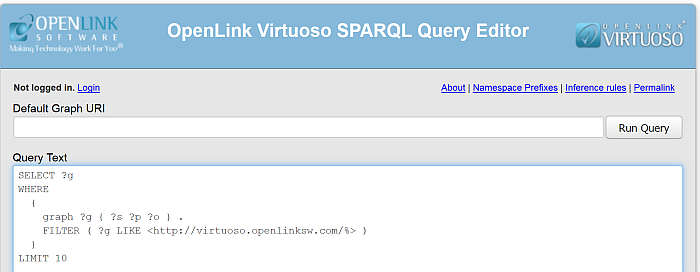
Figure 6.38. Setting up a Content Crawler Job to Retrieve Semantic Sitemap content

Setting up a Content Crawler Job to Retrieve Content from Specific Directories
The following section describes how to set up crawler job for getting directories using Conductor.
-
From the Virtuoso Conductor User Interface i.e. http://cname:port/conductor, login as the "dba" user.
-
Go to "Web Application Server".
Figure 6.39. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
-
Go to "Content Imports".
Figure 6.40. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
-
Click "New Target".
Figure 6.41. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
-
In the shown form:
-
Enter for "Target description":
UDA WebSite
-
Enter for "Target URL":
http://uda.openlinksw.com/
-
Enter for "Copy to local DAV collection" for available user, for ex. demo:
/DAV/home/demo/uda/
-
Choose from the available list "Local resources owner" an user, for ex. demo.
Figure 6.42. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
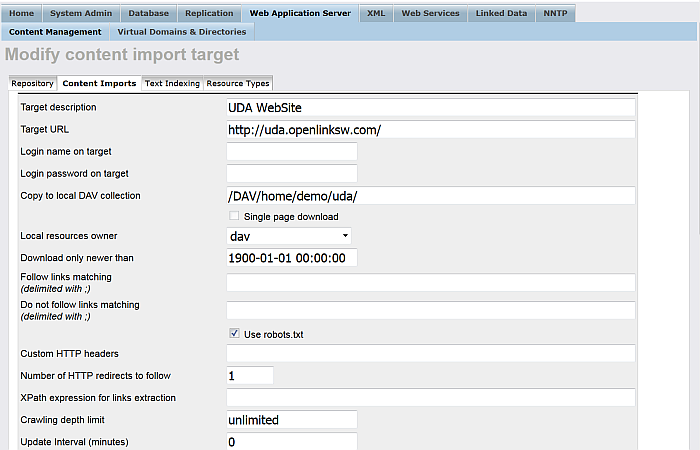
Figure 6.43. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
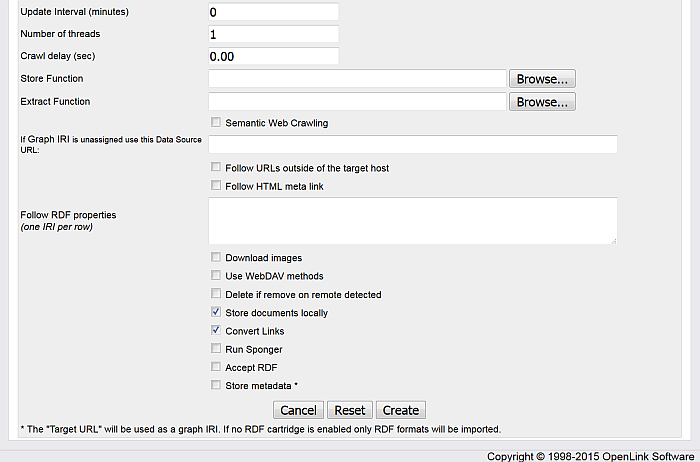
-
Optionally you can select "Convert Link" to make all HREFs in the local stored content relative.
-
Click the button "Create".
-
-
As result the Robot target will be created:
Figure 6.44. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
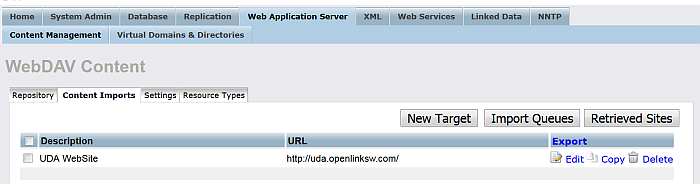
-
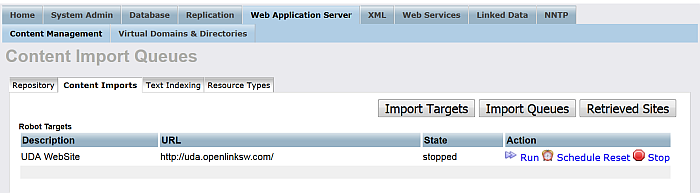
Click "Import Queues".
Figure 6.45. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
-
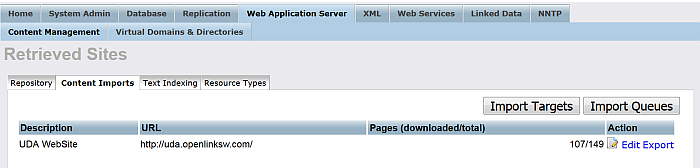
Click "Run" and go to "Retrieved Sites".
-
As result should be shown the number of the total pages retrieved.
Figure 6.46. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
-
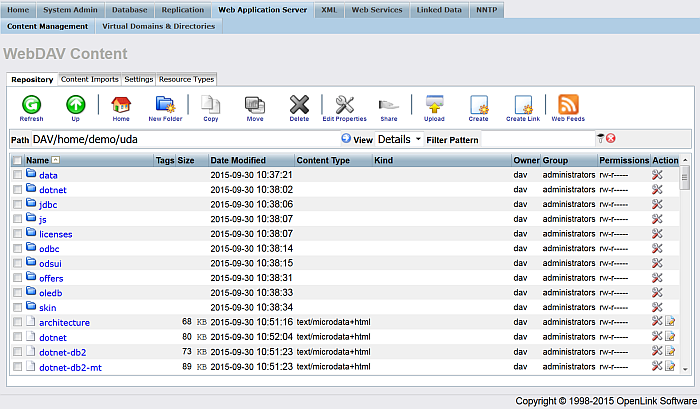
Go to "Web Application Server" -> "Content Management" and go to path:
DAV/home/demo/uda/
-
As result the retrieved content will be shown:
Figure 6.47. Setting up a Content Crawler Job to Retrieve Content from Specific Directories
Setting up a Content Crawler Job to Retrieve Content from ATOM feed
This section demonstrates populating the Virtuoso Quad Store using ATOM feed.
Populating the Virtuoso Quad Store can be done in different ways Virtuoso supports. The Conductor -> Content Import UI offers plenty of options, one of which is the XPath expression for crawling RDF resources URLs and this feature is a powerful and easy-to-use for managing the Quad Store.
To populate the Virtuoso Quad Store, in this Guide we will use a XPAth expression for the URLs of the RDF resources references in a given ATOM feed. For ex. this one of the "National Bibliography" Store.
-
Go to http://cname/conductor
-
Enter dba credentials
-
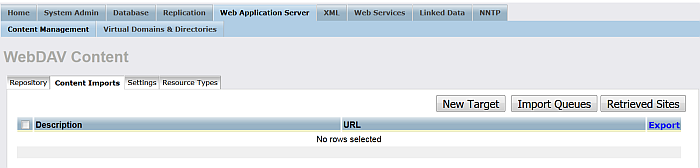
Go to Web Application Server -> Content Management -> Content Imports:
Figure 6.48. Crawling ATOM feed
-
Click "New Target":
Figure 6.49. Crawling ATOM feed
-
In the presented form specify respectively:
-
"Target description": for ex. National Bibliography ;
-
"Target URL": for ex. http://data.libris.kb.se/nationalbibliography/feed/ ;
Note: the entered URL will be the graph URI for storing the imported RDF data. You can also set it explicitly by entering another graph URI in the "If Graph IRI is unassigned use this Data Source URL:" shown as option in this form.
-
"Copy to local DAV collection": for ex.
/DAV/temp/nbio/
-
"XPath expression for links extraction:":
//entry/link/@href
-
"Update Interval (minutes)": for ex. 10 ;
-
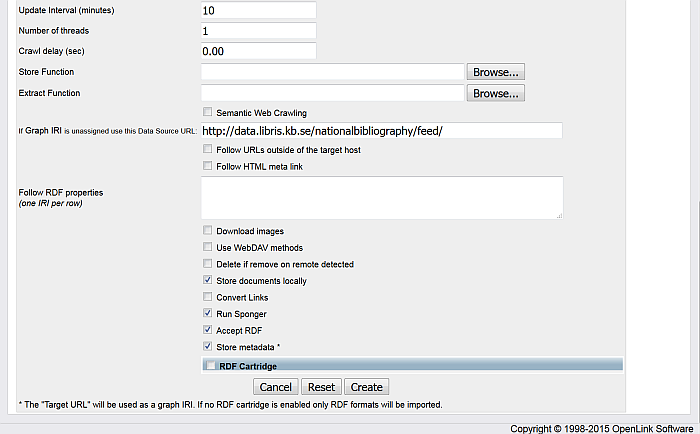
"Run Sponger": hatch this check-box ;
-
"Accept RDF": hatch this check-box ;
-
Optionally you can hatch "Store metadata" ;
-
"RDF Cartridge": hatch this check-box and specify what cartridges will be used.
Figure 6.50. Crawling ATOM feed
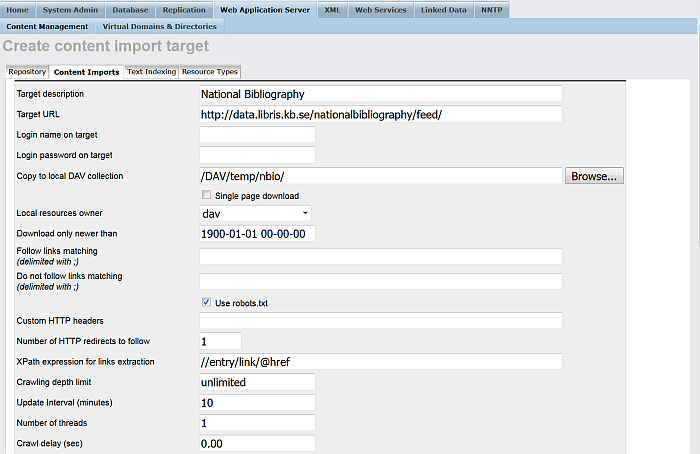
Figure 6.51. Crawling ATOM feed
-
-
Click "Create".
-
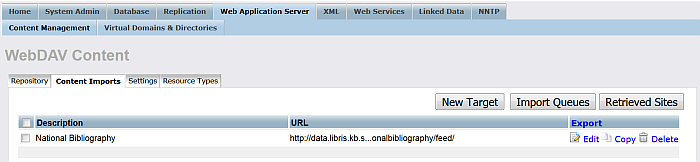
The new created target should be displayed in the list of available Targets:
Figure 6.52. Crawling ATOM feed
-
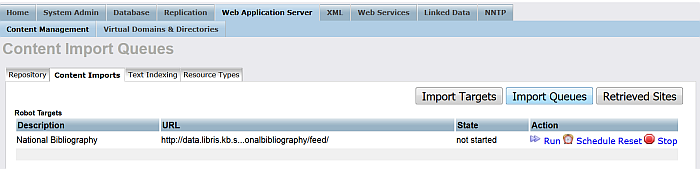
Click "Import Queues":
Figure 6.53. Crawling ATOM feed
-
Click for "National Bibliography" target the "Run" link from the very-right "Action" column.
-
Should be presented list of Top pending URLs:
Figure 6.54. Crawling ATOM feed
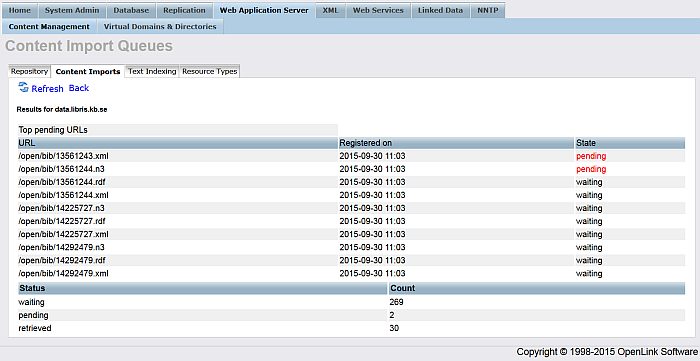
-
Go to "Retrieved Sites" to check the total URLs that were processed:
Figure 6.55. Crawling ATOM feed
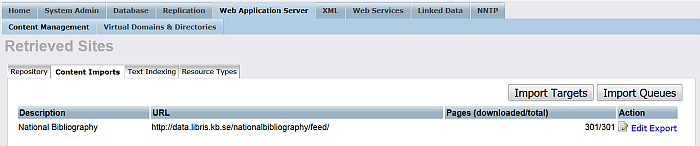
-
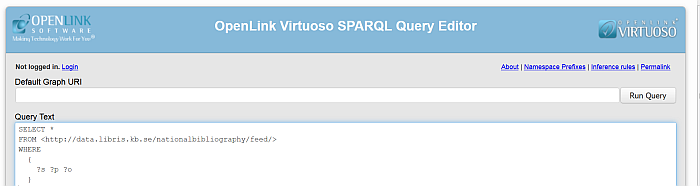
To view the imported RDF data, go to http://example.com/sparql and enter a simple query for ex.:
SELECT * FROM <http://data.libris.kb.se/nationalbibliography/feed/> WHERE { ?s ?p ?o }Figure 6.56. Crawling ATOM feed
-
Click "Run Query".
-
The imported RDF data triples should be shown:
Figure 6.57. Crawling ATOM feed
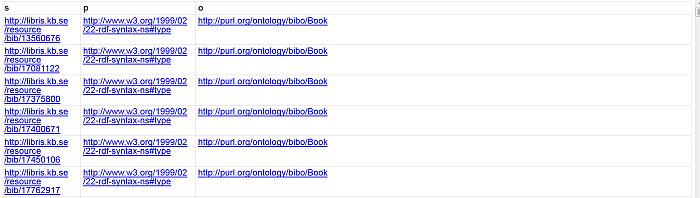
Setting up a Content Crawler Job to Retrieve Content from SPARQL endpoint
The following step-by section walks you through the process of:
-
Populating a Virtuoso Quad Store with data from a 3rd party SPARQL endpoint
-
Generating RDF dumps that are accessible to basic HTTP or WebDAV user agents.
-
Sample SPARQL query producing a list SPARQL endpoints:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dcterms: <http://purl.org/dc/terms/> PREFIX scovo: <http://purl.org/NET/scovo#> PREFIX void: <http://rdfs.org/ns/void#> PREFIX akt: <http://www.aktors.org/ontology/portal#> SELECT DISTINCT ?endpoint WHERE { ?ds a void:Dataset . ?ds void:sparqlEndpoint ?endpoint } -
Here is a sample SPARQL protocol URL constructed from one of the sparql endpoints in the result from the query above:
http://void.rkbexplorer.com/sparql/?query=PREFIX+foaf%3A+%3Chttp%3A%2F%2Fxmlns.com%2Ffoaf%2F0.1%2F%3E+%0D%0APREFIX+void%3A+++++%3Chttp%3A%2F%2Frdfs.org%2Fns%2Fvoid%23%3E++%0D%0ASELECT+distinct+%3Furl++WHERE+%7B+%3Fds+a+void%3ADataset+%3B+foaf%3Ahomepage+%3Furl+%7D%0D%0A&format=sparql
-
Here is the cURL output showing a Virtuoso SPARQL URL that executes against a 3rd party SPARQL Endpoint URL:
$ curl "http://void.rkbexplorer.com/sparql/?query=PREFIX+foaf%3A+%3Chttp%3A%2F%2Fxmlns.com%2Ffoaf%2F0.1%2F%3E+%0D%0APREFIX+void %3A+++++%3Chttp%3A%2F%2Frdfs.org%2Fns%2Fvoid%23%3E++%0D%0ASELECT+distinct+%3Furl++WHERE+%7B+%3Fds+a+void%3ADataset+%3B+foaf%3Ah omepage+%3Furl+%7D%0D%0A&format=sparql" <?xml version="1.0" ?> <sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="url"/> </head> <results ordered="false" distinct="true"> <result> <binding name="url"><uri>http://kisti.rkbexplorer.com/</uri></binding> </result> <result> <binding name="url"><uri>http://epsrc.rkbexplorer.com/</uri></binding> </result> <result> <binding name="url"><uri>http://test2.rkbexplorer.com/</uri></binding> </result> <result> <binding name="url"><uri>http://test.rkbexplorer.com/</uri></binding> </result> ... ... ... </results> </sparql> -
Go to Conductor UI -- http://example.com/conductor and provide dba credentials;
-
Go to "Web Application Server"-> "Content Management" -> "Content Imports"
Figure 6.58. Crawling SPARQL Endpoints
-
Click "New Target":
Figure 6.59. Crawling SPARQL Endpoints
-
In the presented form enter for ex.:
-
"Target description": voiD store
-
"Target URL": the url from above i.e.:
http://void.rkbexplorer.com/sparql/?query=PREFIX+foaf%3A+%3Chttp%3A%2F%2Fxmlns.com%2Ffoaf%2F0.1%2F%3E+%0D%0APREFIX+void%3A+++++%3Chttp%3A%2F%2Frdfs.org%2Fns%2Fvoid%23%3E++%0D%0ASELECT+distinct+%3Furl++WHERE+%7B+%3Fds+a+void%3ADataset+%3B+foaf%3Ahomepage+%3Furl+%7D%0D%0A&format=sparql
-
"Copy to local DAV collection":
/DAV/void.rkbexplorer.com/content
-
"Follow links matching (delimited with ;)":
%
-
Un-hatch "Use robots.txt" ;
-
"XPath expression for links extraction":
//binding[@name="url"]/uri/text()
-
Hatch "Semantic Web Crawling";
-
"If Graph IRI is unassigned use this Data Source URL:": enter for ex:
http://void.collection
-
Hatch "Follow URLs outside of the target host";
-
Hatch "Run "Sponger" and "Accept RDF"
Figure 6.60. Crawling SPARQL Endpoints
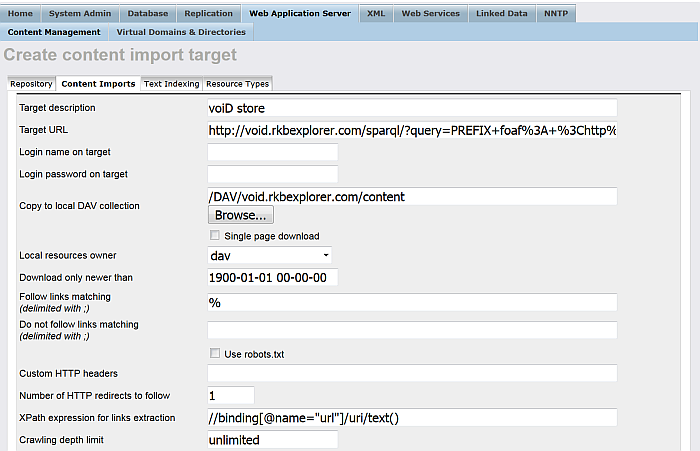
Figure 6.61. Crawling SPARQL Endpoints
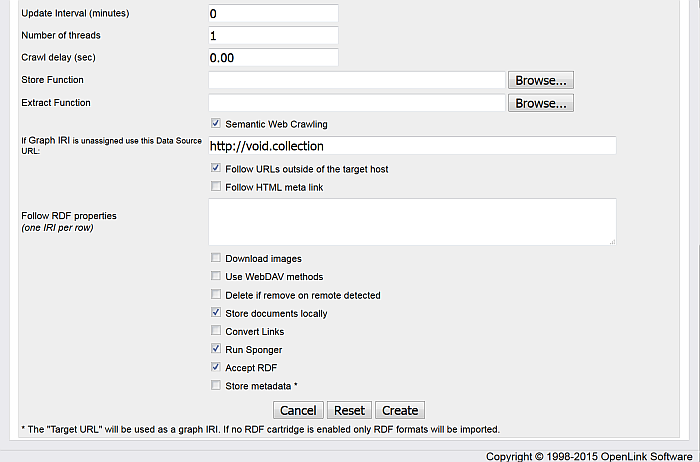
-
-
Click "Create";
-
The target should be created and presented in the list of available targets:
Figure 6.62. Crawling SPARQL Endpoints
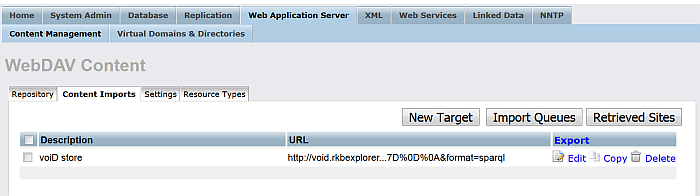
-
Click "Import Queues":
Figure 6.63. Crawling SPARQL Endpoints
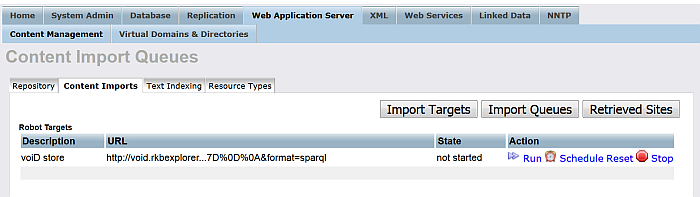
-
Click "Run" for the imported target:
Figure 6.64. Crawling SPARQL Endpoints
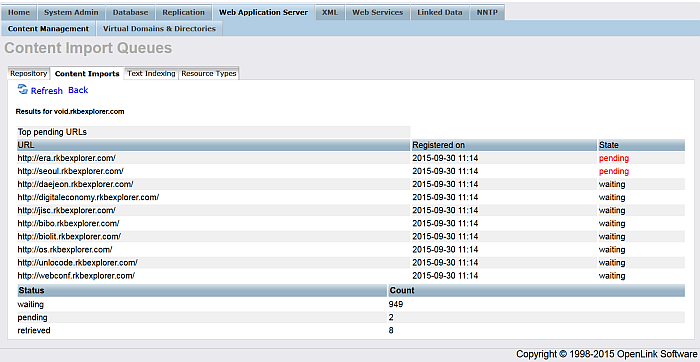
-
To check the retrieved content go to "Web Application Server"-> "Content Management" -> "Content Imports" -> "Retrieved Sites":
Figure 6.65. Crawling SPARQL Endpoints
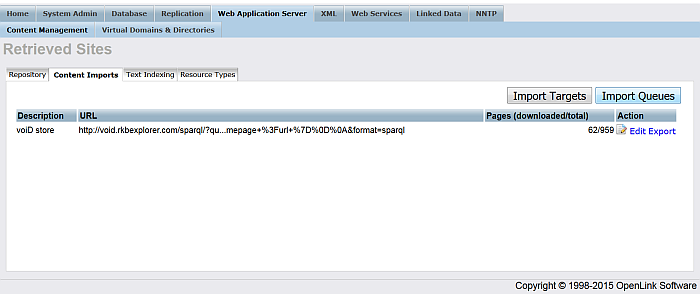
-
Click "voiD store" -> "Edit":
Figure 6.66. Crawling SPARQL Endpoints
-
To check the imported URLs go to "Web Application Server"-> "Content Management" -> "Repository" path DAV/void.rkbexplorer.com/content/:
Figure 6.67. Crawling SPARQL Endpoints
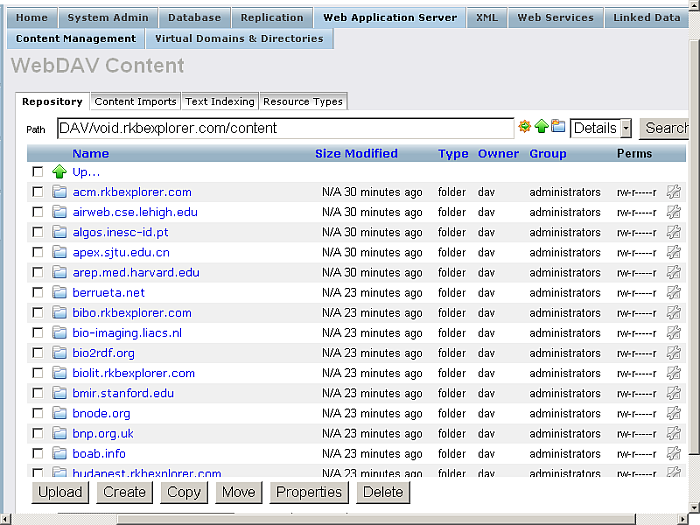
-
To check the inserted into the RDF QUAD data go to http://cname/sparql and execute the following query:
SELECT * FROM <http://void.collection> WHERE { ?s ?p ?o }Figure 6.68. Crawling SPARQL Endpoints
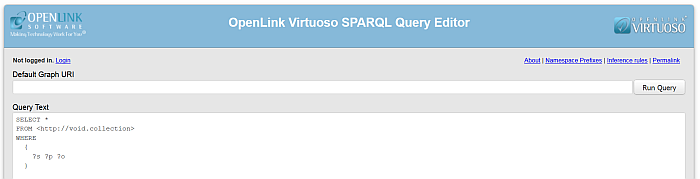
Figure 6.69. Crawling SPARQL Endpoints
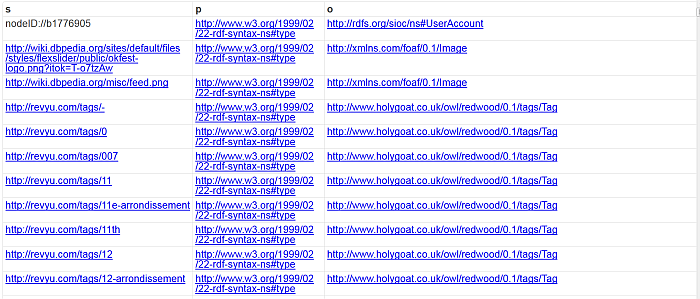
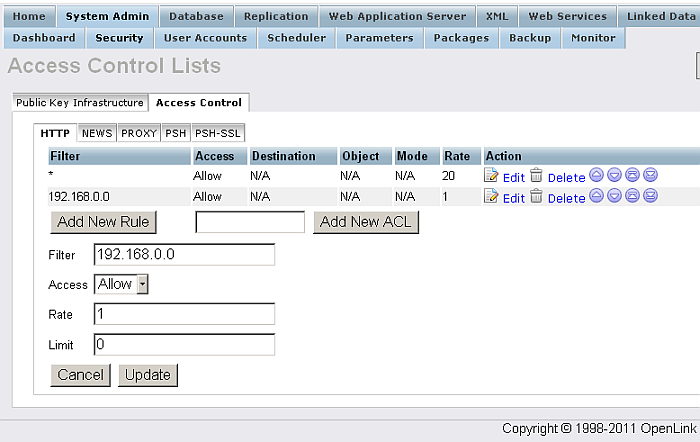
Access Control
From "System Admin" -> Security -> "Access Controls" you can manage Rules and ACL respectively for HTTP, News, Proxy. The tabs PSH and PSH-SSL are available only when the pubsubhub_dav.vad is installed.
Figure 6.70. Access Control Lists
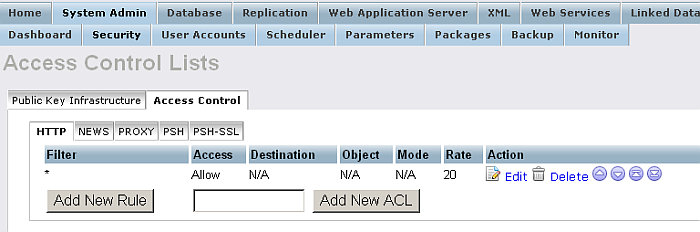
For each of the tabs "HTTP", "NEWS", "PROXY" the created rules will be shown in a list with Filter, Access, Destination, Object, Mode, Rate values. You can also add/delete rules, re-arrange rules order.
Figure 6.71. Access Control List for HTTP
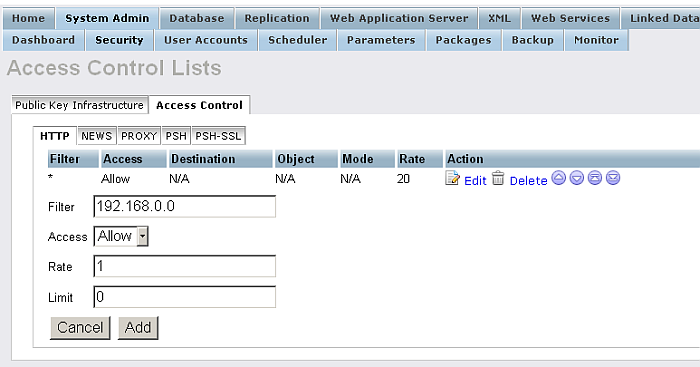
Click the link "Edit" for a rule. Then specify the filter and access values.
Figure 6.72. Access Control Lists
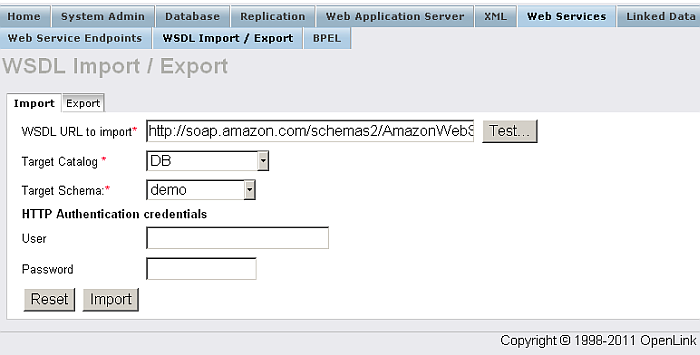
Import WSDL
From "Web Services" / "WSDL Import/Export" you can provide a URL to a WSDL description. In return Virtuoso will automatically provide a wrapper for the services available, hence stored procedures and user-defined types that are callable within Virtuoso while the processing and mechanics of the services are actually handled at the source.
Figure 6.73. WSDL Import
After Virtuoso examines the supplied URL to a WSDL you are presented with the source code for the PL wrappers and Virtuoso user-defined types to be created. You have the chance to edit the code for more specific needs and then you can either save this to a file for later work, or execute it in Virtuoso to create the procedures and types.
Figure 6.74. WSDL Import
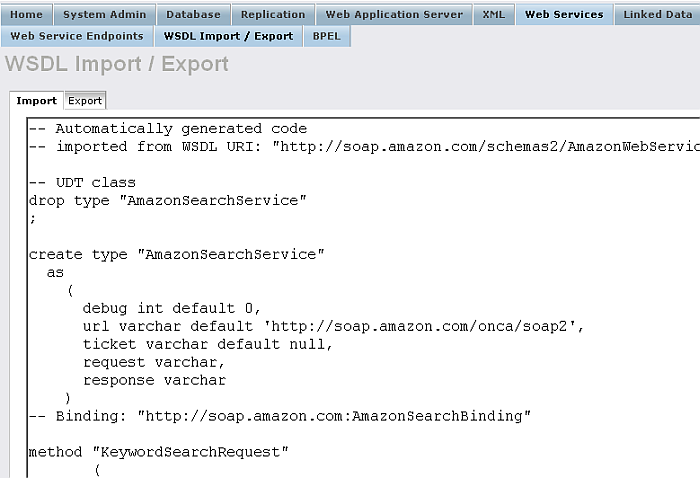
Any errors in the code will be highlighted if you try and execute it.
If you wish to save the file the appropriate file system ACLs must be in place for the destination.