16.18.2. Virtuoso Sesame Provider
What is Sesame
Sesame is an open source Java framework for storing, querying, and reasoning with RDF and RDF Schema. It can be used as a database for RDF and RDF Schema, or as a Java library for applications that need to work with RDF internally. For example, suppose you need to read a big RDF file, find the relevant information for your application, and use that information. Sesame provides you with the necessary tools to parse, interpret, query, and store all this information, embedded in your own application if you want, or, if you prefer, in a separate database or even on a remote server. More generally: Sesame provides an application developer with a toolbox that contains useful hammers, screwdrivers, etc., for 'Do-It-Yourself' projects with RDF.
What is the Virtuoso Sesame Provider
The Virtuoso Sesame Provider is a fully operational Native Graph Model Storage Provider for the Sesame Framework, allowing users of Virtuoso to leverage the Sesame framework to modify, query, and reason with the Virtuoso quad store using the Java language. The Sesame Repository API offers a central access point for connecting to the Virtuoso quad store. Its purpose is to provides a Java-friendly access point to Virtuoso. It offers various methods for querying and updating the data, while abstracting the details of the underlying machinery. The Provider has been tested against the two latest currently available versions, Sesame 2.6.x, 2.7.x, 2.8.x and the new Sesame 4.x release, for which a new Provider is available.
Figure 16.186. Fig. 1 Sesame Component Stack
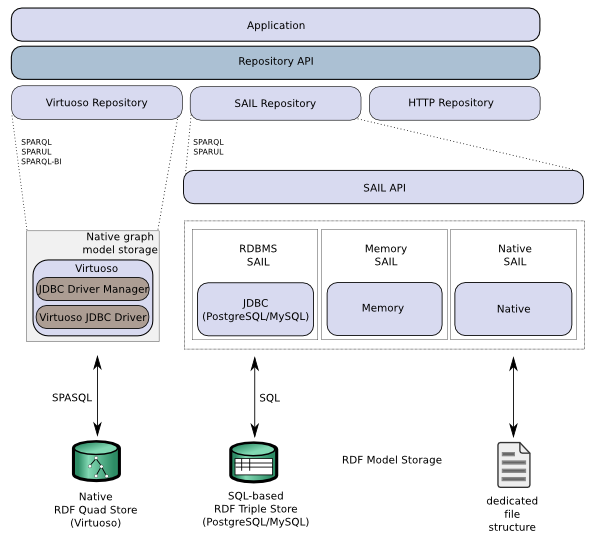
If you need more information about how to set up your environment for working with the Sesame APIs, take a look at Chapter 2 of the Sesame User Guide, Setting up to use the Sesame libraries .
Setup
Required Files
This tutorial assumes you have Virtuoso server installed and that the database is accessible at "localhost:1111". In addition, the relevant version of the Virtuoso Sesame Provider, and Sesame java framework need to be installed.
You should download the Virtuoso Sesame Provider JAR archive for the version of Sesame being used, Virtuoso JDBC Driver, Sesame Framework and associated classes and sample programs from our download page . Note the version of the Sesame Provider (virt_sesameX.jar) can be determined with the command:
$ java -jar virt_sesame2.jar OpenLink Virtuoso(TM) Provider for Sesame2(TM) Version 2.6.5 [Build 1.7] $ java -jar virt_sesame4.jar OpenLink Virtuoso(TM) Provider for Sesame4(TM) Version 4.0.0 [Build 0.1] $
Sesame 2 Sample Program
Compilation
-
Ensure that full paths to the following files, or equivalents for your version of Sesame, are all included in the active CLASSPATH setting --
-
openrdf-sesame-2.1.2-onejar.jar
-
slf4j-api-1.5.0.jar
-
slf4j-jdk14-1.5.0.jar
-
commons-io-2.0.jar
-
virtjdbc3.jar
-
virt_sesame2.jar
-
-
Execute the following command:
javac VirtuosoTest.java
Note: we recommend adding the following to the connect string, to use utf-8 and row-auto-commit:
"/charset=UTF-8/log_enable=2" -- i.e. in VirtuosoTest.java the line: Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1], sa[2], sa[3]); -- should become: Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1]+ "/charset=UTF-8/log_enable=2", sa[2], sa[3]);
Testing
-
Ensure that full paths to the following files are all included in the active CLASSPATH setting (note the addition of virtuoso_driver, here):
-
openrdf-sesame-2.1.2-onejar.jar
-
slf4j-api-1.5.0.jar
-
slf4j-jdk14-1.5.0.jar
-
commons-io-2.0.jar
-
virtjdbc3.jar
-
virt_sesame2.jar
-
virtuoso_driver
-
-
Run the VirtuosoTest program to test the Sesame 2 Provider with the following command:
java VirtuosoTest <hostname> <port> <uid> <pwd>
-
The test run should look like this:
$ java VirtuosoTest localhost 1111 dba dba == TEST 1: : Start Loading data from URL: http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com/foaf.rdf == TEST 1: : End PASSED: TEST 1 == TEST 2: : Start Clearing triple store == TEST 2: : End PASSED: TEST 2 == TEST 3: : Start Loading data from file: virtuoso_driver/data.nt == TEST 3: : End PASSED: TEST 3 == TEST 4: : Start Loading UNICODE single triple == TEST 4: : End PASSED: TEST 4 == TEST 5: : Start Loading single triple == TEST 5: : End PASSED: TEST 5 == TEST 6: : Start Casted value type == TEST 6: : End PASSED: TEST 6 == TEST 7: : Start Selecting property == TEST 7: : End PASSED: TEST 7 == TEST 8: : Start Statement does not exists == TEST 8: : End PASSED: TEST 8 == TEST 9: : Start Statement exists (by resultset size) == TEST 9: : End PASSED: TEST 9 == TEST 10: : Start Statement exists (by hasStatement()) == TEST 10: : End PASSED: TEST 10 == TEST 11: : Start Retrieving namespaces == TEST 11: : End PASSED: TEST 11 == TEST 12: : Start Retrieving statement (http://myopenlink.net/dataspace/person/kidehen http://myopenlink.net/foaf/name null) == TEST 12: : End PASSED: TEST 12 == TEST 13: : Start Writing the statements to file: (/Users/src/virtuoso-opensource/binsrc/sesame2/results.n3.txt) == TEST 13: : End PASSED: TEST 13 == TEST 14: : Start Retrieving graph ids == TEST 14: : End PASSED: TEST 14 == TEST 15: : Start Retrieving triple store size == TEST 15: : End PASSED: TEST 15 == TEST 16: : Start Sending ask query == TEST 16: : End PASSED: TEST 16 == TEST 17: : Start Sending construct query == TEST 17: : End PASSED: TEST 17 == TEST 18: : Start Sending describe query == TEST 18: : End PASSED: TEST 18 ============================ PASSED:18 FAILED:0
Sesame 4 Sample Program
Compilation
-
Ensure that full paths to the following files, or equivalents for your version of Sesame, are all included in the active CLASSPATH setting --
-
openrdf-sesame-4.0.0-onejar.jar
-
slf4j-api-1.7.10.jar
-
commons-io-2.4.jar
-
virtjdbc4.jar
-
virt_sesame4.jar
-
-
Execute the following command:
javac VirtuosoTest.java
Note: we recommend adding the following to the connect string, to use utf-8 and row-auto-commit:
"/charset=UTF-8/log_enable=2" -- i.e. in VirtuosoTest.java the line: Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1], sa[2], sa[3]); -- should become: Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1]+ "/charset=UTF-8/log_enable=2", sa[2], sa[3]);
Testing
-
Ensure that full paths to the following files are all included in the active CLASSPATH setting (note the addition of virtuoso_driver, here):
-
openrdf-sesame-4.0.0-onejar.jar
-
slf4j-api-1.7.10.jar
-
commons-io-2.4.jar
-
virtjdbc4.jar
-
virt_sesame4.jar
-
virtuoso_driver
-
-
Run the VirtuosoTest program to test the Sesame 2 Provider with the following command:
java VirtuosoTest <hostname> <port> <uid> <pwd>
-
The test run should look like this:
$ java VirtuosoTest localhost 1111 dba dba == TEST 1: : Start == TEST 1: : End PASSED: TEST 1 == TEST 2: : Start Loading data from URL: http://dbpedia.org/data/Berlin.rdf log4j:WARN No appenders could be found for logger (org.openrdf.rio.RDFParserRegistry). log4j:WARN Please initialize the log4j system properly. == TEST 2: : End PASSED: TEST 2 == TEST 3: : Start Clearing triple store == TEST 3: : End PASSED: TEST 3 == TEST 4: : Start Loading data from file: virtuoso_driver/data.nt == TEST 4: : End PASSED: TEST 4 == TEST 5: : Start Loading UNICODE single triple == TEST 5: : End PASSED: TEST 5 == TEST 6: : Start Loading single triple == TEST 6: : End PASSED: TEST 6 == TEST 7: : Start Casted value type == TEST 7: : End PASSED: TEST 7 == TEST 8: : Start Selecting property == TEST 8: : End PASSED: TEST 8 == TEST 9: : Start Statement does not exists == TEST 9: : End PASSED: TEST 9 == TEST 10: : Start Statement exists (by resultset size) == TEST 10: : End PASSED: TEST 10 == TEST 11: : Start Statement exists (by hasStatement()) == TEST 11: : End PASSED: TEST 11 == TEST 12: : Start Retrieving namespaces == TEST 12: : End PASSED: TEST 12 == TEST 13: : Start Retrieving statement (http://myopenlink.net/dataspace/person/kidehen http://myopenlink.net/foaf/name null) == TEST 13: : End PASSED: TEST 13 == TEST 14: : Start Writing the statements to file: (/Users/hwilliams/src/git/vos-7-develop/binsrc/sesame4/results.n3.txt) == TEST 14: : End PASSED: TEST 14 == TEST 15: : Start Retrieving graph ids == TEST 15: : End PASSED: TEST 15 == TEST 16: : Start Retrieving triple store size == TEST 16: : End PASSED: TEST 16 == TEST 17: : Start Sending ask query == TEST 17: : End PASSED: TEST 17 == TEST 18: : Start Sending construct query == TEST 18: : End PASSED: TEST 18 == TEST 19: : Start Sending describe query == TEST 19: : End PASSED: TEST 19 ============================ PASSED:19 FAILED:0
Getting Started
This section covers the essentials for connecting to and manipulating data stored in a Virtuoso repository using the Sesame API. More information on the Sesame Framework, including extended examples on how to use the API, can be found in Chapter 8 of the Sesame User's guide, the RepositoryConnection API .
The interfaces for the Repository API can be found in packages virtuoso.sesame2.driver and org.openrdf.repository. Several implementations for these interfaces exist in the Virtuoso Provider download package. The Javadoc reference for the Sesame API is available online and can also be found in the doc directory of the download.
Creating a Virtuoso Repository RDF object
The first step to connecting to Virtuoso through the Sesame API is to create a Repository for it. The Repository object operates on (stacks of) Sail object(s) for storage and retrieval of RDF data.
One of the simplest configurations is a repository that just stores RDF data in main memory, without applying any inference. This is also by far the fastest type of repository that can be used. The following code creates and initialize a non-inferencing main-memory repository:
import virtuoso.sesame2.driver.VirtuosoRepository;
Repository myRepository = VirtuosoRepository("jdbc:virtuoso://localhost:1111","dba","dba");
myRepository.initialize();
The constructor of the VirtuosoRepository class accepts the JDBC URL of the Virtuoso engine, and the username and password of an authorized user. Following this example, the repository needs to be initialized to prepare the Sail(s) that it operates on, which includes performing operations such as restoring previously stored data, setting up connections to a relational database, etc.
The repository that is created by the above code is volatile: its contents are lost when the object is garbage collected or when the program is shut down. This is fine for cases where, for example, the repository is used as a means for manipulating an RDF model in memory.
Creating a Virtuoso Repository Connection
Now that we have created a VirtuosoRepository object instance, we want to do something with it. This is achieved through the use of the VirtuosoRepositoryConnection class, which can be created by the VirtuosoRepository class.
A VirtuosoRepositoryConnection represents as the name suggests a connection to the actual Virtuoso quad store. We can issue operations over this connection, and close it when we are done to make sure we are not keeping resources unnecessarily occupied.
In the following sections, we will show some examples of basic operations using the Northwind dataset.
Adding RDF to Virtuoso
The Repository implements the Sesame Repository API, which offers various methods for adding data to a repository. Data can be added programmatically by specifying the location of a file that contains RDF data, and statements can be added individually or in collections.
We perform operations on the repository by requesting a RepositoryConnection from the repository, which returns a VirtuosoRepositoryConnection object. On this VirtuosoRepositoryConnection object we can perform the various operations, such as query evaluation; getting, adding, or removing statements; etc.
The following example code adds two files, one local and one located on the Web, to a repository:
import org.openrdf.repository.RepositoryException;
import org.openrdf.repository.Repository;
import org.openrdf.repository.RepositoryConnection;
import org.openrdf.rio.RDFFormat;
import java.io.File;
import java.net.URL;
File file = new File("/path/to/example.rdf");
String baseURI = "http://example.org/example/localRDF";
?
try {
RepositoryConnection con = myRepository.getConnection();
try {
con.add(file, baseURI, RDFFormat.RDFXML);
URL url = new URL("http://example.org/example/remoteRDF");
con.add(url, url.toString(), RDFFormat.RDFXML);
}
finally {
con.close();
}
}
catch (RepositoryException rex) {
// handle exception
}
catch (java.io.IOEXception e) {
// handle io exception
}
More information on other available methods can be found in the javadoc reference of the RepositoryConnection interface.
Querying Virtuoso
The Repository API has a number of methods for creating and evaluating queries. Three types of queries are distinguished: tuple queries, graph queries, and Boolean queries. The query types differ in the type of results that they produce.
Select Query: The result of a select query is a set of tuples (or variable bindings), where each tuple represents a solution of the query. This type of query is commonly used to get specific values (URIs, blank nodes, literals) from the stored RDF data. The method QueryFactory.executeQuery() returns a Value [ ][ ] for SPARQL "SELECT" queries. The method QueryFactory.executeQuery() also calls the QueryFactory.setResult() which populates a set of tuples for SPARQL "SELECT" queries. The graph can be retrieved using QueryFactory.getBooleanResult().
Graph Query: The result of a graph query is an RDF graph (or set of statements). This type of query is very useful for extracting sub-graphs from the stored RDF data, which can then be queried further, serialized to an RDF document, etc. The method QueryFactory.executeQuery() calls the QueryFactory.setGraphResult() which populates a graph for SPARQL "DESCRIBE" and "CONSTRUCT" queries. The graph can be retrieved using QueryFactory.getGraphResult().
Boolean Query: The result of a Boolean query is a simple Boolean value, i.e., TRUE or FALSE. This type of query can be used to check if a repository contains specific information. The method QueryFactory.executeQuery() calls the QueryFactory.setBooleanResult() which sets a Boolean value for SPARQL "ASK" queries. The value can be retrieved using QueryFactory.getBooleanResult().
Note: Although Sesame 2 currently supports two query languages: SeRQL and SPARQL, the Virtuoso provider only supports the W3C SPARQL specification at this time.
Evaluating a SELECT Query
To evaluate a tuple query we simply do the following:
import java.util.List;
import org.openrdf.OpenRDFException;
import org.openrdf.repository.RepositoryConnection;
import org.openrdf.query.TupleQuery;
import org.openrdf.query.TupleQueryResult;
import org.openrdf.query.BindingSet;
import org.openrdf.query.QueryLanguage;
?
try {
RepositoryConnection con = myRepository.getConnection();
try {
String queryString = "SELECT x, y FROM WHERE {x} p {y}";
TupleQuery tupleQuery = con.prepareTupleQuery(QueryLanguage.SPARQL, queryString);
TupleQueryResult result = tupleQuery.evaluate();
try {
? // do something with the result
}
finally {
result.close();
}
}
finally {
con.close();
}
}
catch (RepositoryException e) {
// handle exception
}
This evaluates a SPARQL query and returns a TupleQueryResult, which consists of a sequence of BindingSet objects. Each BindingSet contains a set of pairs called Binding objects. A Binding object represents a name/value pair for each variable in the query's projection.
We can use the TupleQueryResult to iterate over all results and get each individual result for x and y:
while (result.hasNext()) {
BindingSet bindingSet = result.next();
Value valueOfX = bindingSet.getValue("x");
Value valueOfY = bindingSet.getValue("y");
// do something interesting with the query variable values here?
}
As you can see, we retrieve values by name rather than by an index. The names used should be the names of variables as specified in your query. The TupleQueryResult.getBindingNames() method returns a list of binding names, in the order in which they were specified in the query. To process the bindings in each binding set in the order specified by the projection, you can do the following:
List bindingNames = result.getBindingNames();
while (result.hasNext()) {
BindingSet bindingSet = result.next();
Value firstValue = bindingSet.getValue(bindingNames.get(0));
Value secondValue = bindingSet.getValue(bindingNames.get(1));
// do something interesting with the values here?
}
It is important to invoke the close() operation on the TupleQueryResult, after we are done with it. A TupleQueryResult evaluates lazily and keeps resources (such as connections to the underlying database) open. Closing the TupleQueryResult frees up these resources. Do not forget that iterating over a result may cause exceptions! The best way to make sure no connections are kept open unnecessarily is to invoke close() in the finally clause.
An alternative to producing a TupleQueryResult is to supply an object that implements the TupleQueryResultHandler interface to the query's evaluate() method. The main difference is that when using a return object, the caller has control over when the next answer is retrieved, whereas with the use of a handler, the connection simply pushes answers to the handler object as soon as it has them available.
As an example we will use SPARQLResultsXMLWriter, which is a TupleQueryResultHandler implementation that writes SPARQL Results XML documents to an output stream or to a writer:
import org.openrdf.query.resultio.sparqlxml.SPARQLResultsXMLWriter;
?
FileOutputStream out = new FileOutputStream("/path/to/result.srx");
try {
SPARQLResultsXMLWriter sparqlWriter = new SPARQLResultsXMLWriter(out);
RepositoryConnection con = myRepository.getConnection();
try {
String queryString = "SELECT * FROM WHERE {x} p {y}";
TupleQuery tupleQuery = con.prepareTupleQuery(QueryLanguage.SPARQL, queryString);
tupleQuery.evaluate(sparqlWriter);
}
finally {
con.close();
}
}
finally {
out.close();
}
You can just as easily supply your own application-specific implementation of TupleQueryResultHandler, if desired.
Lastly, an important warning: as soon as you are done with the RepositoryConnection object, you should close it. Notice that during processing of the TupleQueryResult object (for example, when iterating over its contents), the RepositoryConnection should still be open. We can invoke con.close() after we have finished with the result.
Evaluating a CONSTRUCT query
The following code evaluates a graph query on a repository:
import org.openrdf.query.GraphQueryResult;
GraphQueryResult graphResult = con.prepareGraphQuery(
QueryLanguage.SPARQL, "CONSTRUCT * FROM {x} p {y}").evaluate();
A GraphQueryResult is similar to TupleQueryResult in that it is an object that iterates over the query results. However, for graph queries the query results are RDF statements, so a GraphQueryResult iterates over Statement objects:
while (graphResult.hasNext()) {
Statement st = graphResult.next();
// ? do something with the resulting statement here.
}
The TupleQueryResultHandler equivalent for graph queries is org.openrdf.rio.RDFHandler. Again, this is a generic interface; each object implementing it can process the reported RDF statements in any way it wants.
All writers from Rio (such as the RDFXMLWriter, TurtleWriter, TriXWriter, etc.) implement the RDFHandler interface. This allows them to be used in combination with querying quite easily. In the following example, we use a TurtleWriter to write the result of a SPARQL graph query to standard output in Turtle format:
import org.openrdf.rio.turtle.TurtleWriter;
?
RepositoryConnection con = myRepository.getConnection();
try {
TurtleWriter turtleWriter = new TurtleWriter(System.out);
con.prepareGraphQuery(QueryLanguage.SPARQL, "CONSTRUCT * FROM WHERE {x} p {y}").evaluate(turtleWriter);
}
finally {
con.close();
}
Again, note that as soon as we are done with the result of the query (either after iterating over the contents of the GraphQueryResult or after invoking the RDFHandler), we invoke con.close() to close the connection and free resources.
Javadoc API Documentation
Javadocs covers the complete set of classes, interfaces, and methods implemented by the provider:
Virtuoso Sesame HTTP Repository Configuration and Usage
What
Sesame is an open source Java framework for storing, querying and reasoning with RDF and RDF Schema. It can be used as a database for RDF and RDF Schema, or as a Java library for applications that need to work with RDF internally. The Sesame HTTP repository serves as a proxy for a RDF store hosted on a remote Sesame server, enabling the querying of the RDF store using the Sesame HTTP protocol.
Why
The Sesame HTTP repository endpoint provides users with the greater flexibility for manipulating the RDF store via a common interface. Sesame provides you with the necessary tools to parse, interpret, query and store all this information, embedded in your own application if you want, or, if you prefer, in a separate database or even on a remote server.
How
To create a new Sesame HTTP repository, the Console needs to create such an RDF document and submit it to the SYSTEM repository. The Console uses so called repository configuration templates to accomplish this. Repository configuration templates are simple Turtle RDF files that describe a repository configuration, where some of the parameters are replaced with variables. The Console parses these templates and asks the user to supply values for the variables. The variables are then substituted with the specified values, which produces the required configuration data.
Setup and Testing
This section details the steps required for configuring and testing a Virtuoso Sesame Repository, both using the HTTP and Console Sesame repositories.
Requirements
-
Sesame 2.3.1 or higher
-
Virtuoso Sesame 2.x (virt_sesame2.jar) or Virtuoso Sesame 4.x (virt_sesame4.jar) Provider
-
Virtuoso JDBC Driver (virtjdbc4.jar)
-
Virtuoso System Repository config file for Sesame 2.x or Sesame 4.x (create.xsl)
-
Virtuoso Repository config file for Sesame 2.x or Sesame 4.x (create-virtuoso.xsl)
-
Configuration Template file for a Virtuoso Repository for Sesame 2.x or Sesame 4.x
-
Apache Tomcat version 5 or higher
Setup Sesame HTTP Repository
This section details the steps required for configuring and testing a Virtuoso HTTP Sesame Repository.
-
Install Apache Tomcat web server
-
From the Sesame 2.3.1 or higher "lib" directory copy the "openrdf-sesame.war" and "openrdf-worbbench.war" files to the tomcat "webapps" directory where they will automatically be deployed creating two new sub directories "openrdf-sesame" and "openrdf-workbench".
-
Place the corresponding Virtuoso Sesame Provider "virt_sesame2.jar" or "virt_sesame4.jar" and JDBC Driver "virtjdbc4.jar" into the Tomcat ~/webapps/openrdf-sesame/WEB-INF/lib/ and ~/webapps/openrdf-workbench/WEB-INF/lib/ directories for use by the Sesame HTTP Repository for accessing the Virtuoso RDF repository.
-
Place the "create.xsl" and "create-virtuoso.xsl" files in the Tomcat ~/webapps/openrdf-workbench/transformations/ directory. Note "create.xsl" replaces the default provided with Sesame and contains the necessary entries required to reference the new "create-virtuoso.xsl" template file for Virtuoso repository configuration.
-
The Sesame HTTP Repository will now be accessible on the URLs
http://example.com/openrdf-sesame http://example.com/openrdf-workbench
-
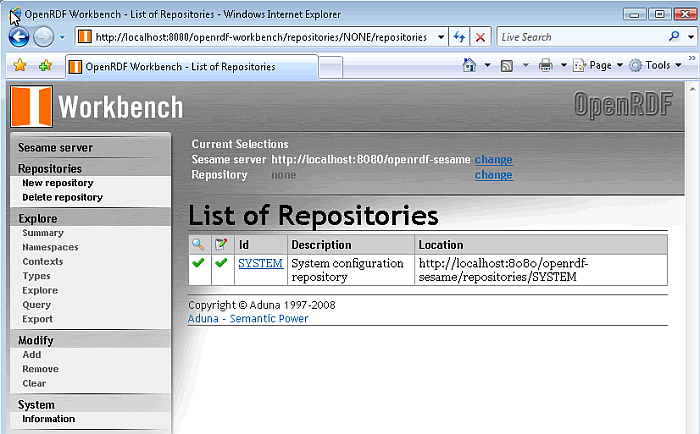
The Sesame OpenRDF Workbench is used for accessing the Sesame HTTP Repositories, loading " http://example.com/openrdf-workbench " will enable the default "SYSTEM" repository to be accessed.
Figure 16.187. Virtuoso Sesame HTTP Repository Configuration and Usage
-
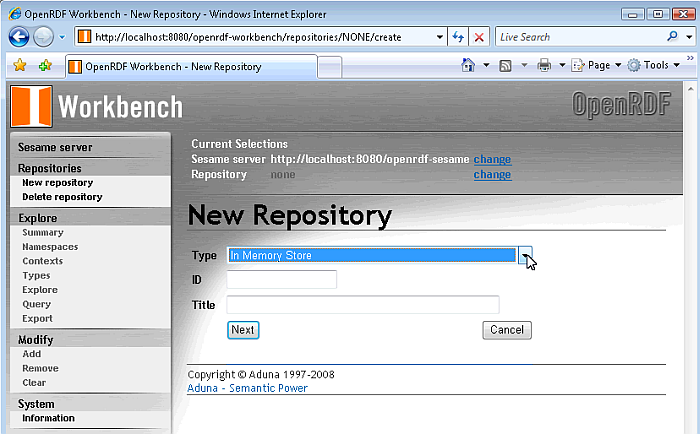
Click on the "New Repository" link in the left frame to create a new Sesame Repository.
Figure 16.188. Virtuoso Sesame HTTP Repository Configuration and Usage
-
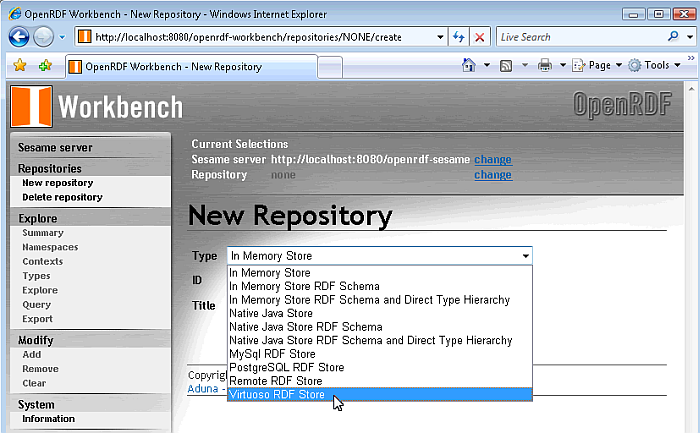
Select the "Virtuoso RDF Store" from the "Type" drop down list box presented.
Figure 16.189. Virtuoso Sesame HTTP Repository Configuration and Usage
-
Choose suitable repository "ID" and "Title" for the Virtuoso repository to be created and click "Next".
Figure 16.190. Virtuoso Sesame HTTP Repository Configuration and Usage
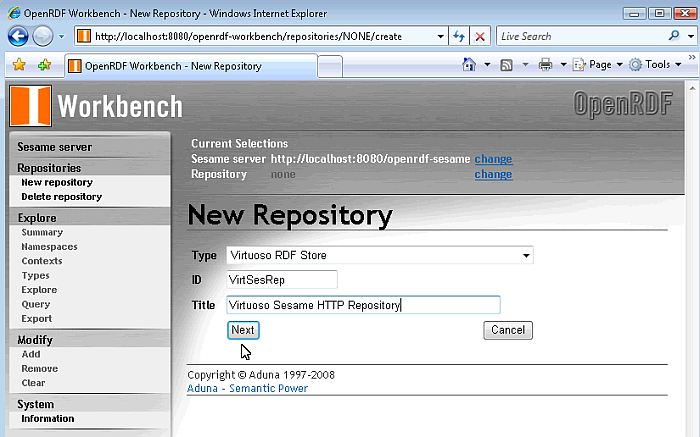
-
Fill in the connection parameters for the target Virtuoso sever the repository is to be created for and click the "create" button. The minimum required are the hostname, port number, username and password of the Virtuoso Server.
Figure 16.191. Virtuoso Sesame HTTP Repository Configuration and Usage
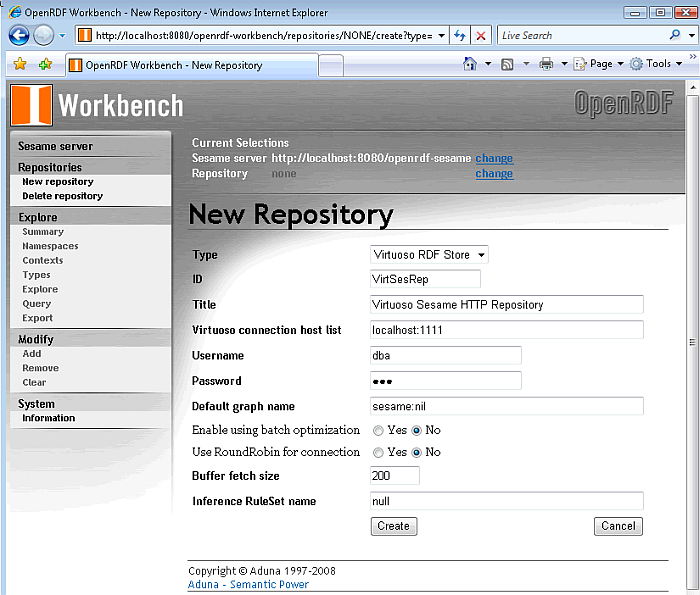
-
The new Virtuoso respository will be created and its summary page displayed.
Figure 16.192. Virtuoso Sesame HTTP Repository Configuration and Usage

-
Click on the "Namespaces" link in the left frame to obtain a list of the available namespaces in the Virtuoso repository.
Figure 16.193. Virtuoso Sesame HTTP Repository Configuration and Usage
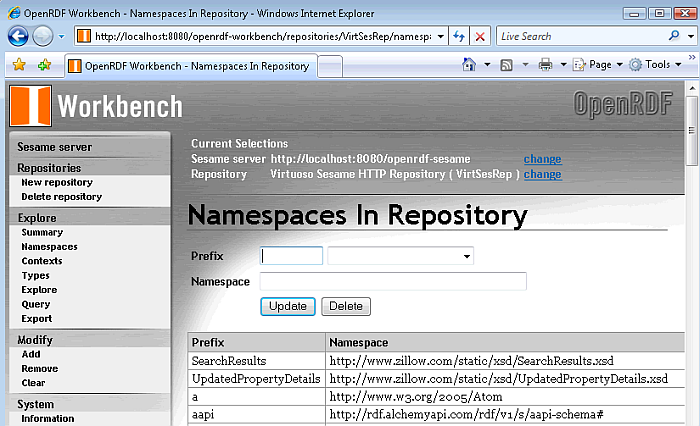
-
Click on the "Context" link in the left frame to obtain a list of the available contexts in the Virtuoso repository.
Figure 16.194. Virtuoso Sesame HTTP Repository Configuration and Usage
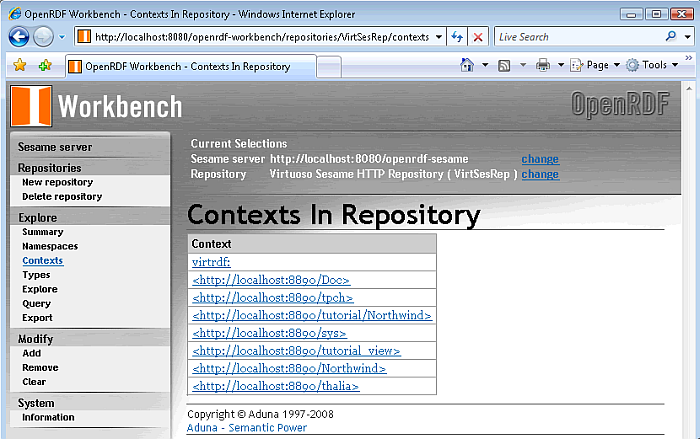
-
Click on the "Types" link in the left frame to obtain a list of the available types in the Virtuoso repository.
Figure 16.195. Virtuoso Sesame HTTP Repository Configuration and Usage
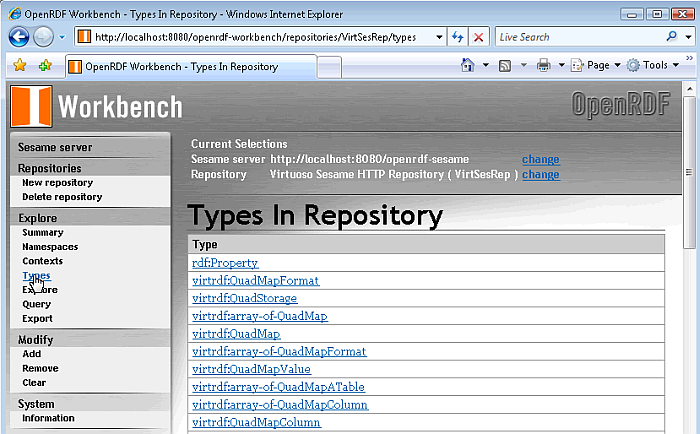
-
Click on the "Query" link in the left frame, enter a suitable SPARQL query to execute against the Virtuoso repository and click the "execute" button.
Figure 16.196. Virtuoso Sesame HTTP Repository Configuration and Usage
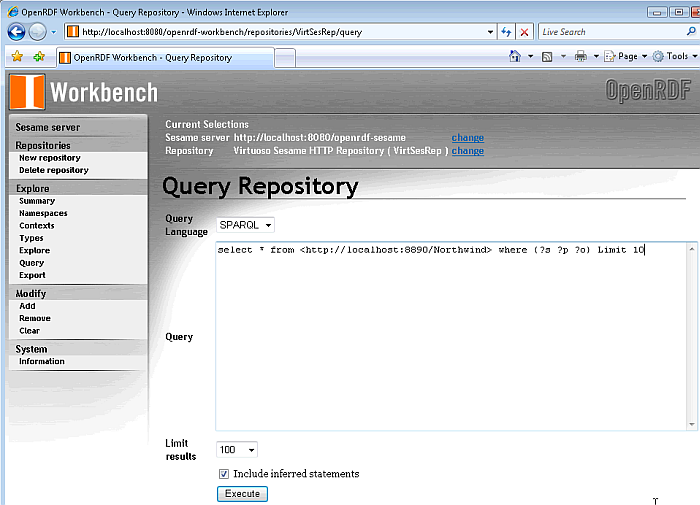
-
The results of the SPARQL query are returned.
Figure 16.197. Virtuoso Sesame HTTP Repository Configuration and Usage
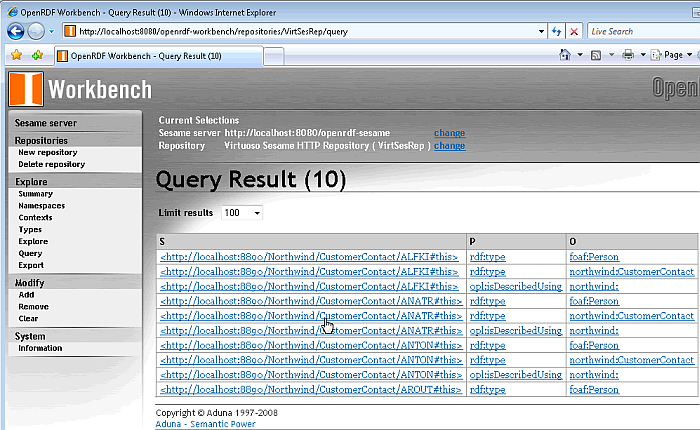
-
Click on the "Repositories" link in the left frame and the newly created Virtuoso repository entry is displayed along side the default SYSTEM repository.
Figure 16.198. Virtuoso Sesame HTTP Repository Configuration and Usage
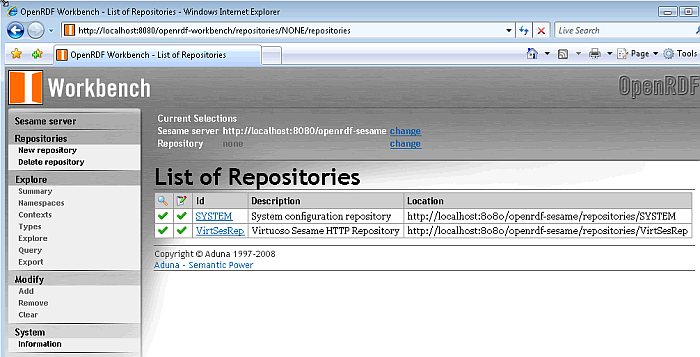
Setup Sesame Console Repository
This section details the steps required for configuring and testing a Virtuoso Sesame Console Repository:
-
Extract Sesame 2.3.1 or higher archive to a location of choice and place the virt_sesame2.jar or virt_sesame4.jar and virtjdbc4.jar files to the sesame "lib" directory
-
Start the sesame console application by running the "console.bat" script in the sesame "bin" directory and then "exit." the program
$ sh console.sh SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/Users/myuser/openrdf-sesame-2.3.1/lib/logback-classic-0.9.18.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/Users/myuser/openrdf-sesame-2.3.1/lib/slf4j-jdk14-1.5.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 10:32:38.317 [main] DEBUG info.aduna.platform.PlatformFactory - os.name <http://os.name> <http://os.name> = mac os x 10:32:38.351 [main] DEBUG info.aduna.platform.PlatformFactory - Detected Mac OS X platform Connected to default data directory Commands end with '.' at the end of a line Type 'help.' for help exit.
-
This will create the necessary sesame application data directories as detailed in the sesame data directory configuration documentation.
Windows - C:\Documents and Settings\LocalService\Application Data\Aduna\ Mac OS X - /Users/myuser/Library/Application Support/Aduna/ Linux - $HOME/.aduna/
-
If you do not want to use the default sesame data directory location the Sesame console application can be started by specifying a custom data directory location with the "-d" option. Note in this case the directory "OpenRDF Sesame console" always has to be manually appended to the directory as Sesame assumes the data file will reside in a sub directory of this name.
$ sh console.sh -d /Users/myuser/OpenRDF Sesame console
-
Add the virtuoso.ttl file to the ~/OpenRDF Sesame console/templates folder, to enable the Virtuoso repository default configuration parameters to be located.
-
Start the sesame console application with the required data directory location and create a Virtuoso repository as detailed in the steps below, the key parameters to be specified being the target Virtuoso server hostname, port number, username, password and a unique "Repository ID".
$ sh console.sh SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/Users/myuser/openrdf-sesame-2.3.1/lib/logback-classic-0.9.18.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/Users/myuser/openrdf-sesame-2.3.1/lib/slf4j-jdk14-1.5.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 10:32:38.317 [main] DEBUG info.aduna.platform.PlatformFactory - os.name <http://os.name> <http://os.name> = mac os x 10:32:38.351 [main] DEBUG info.aduna.platform.PlatformFactory - Detected Mac OS X platform Connected to default data directory Commands end with '.' at the end of a line Type 'help.' for help create virtuoso . Please specify values for the following variables: Host list [localhost:1111]: Username [dba]: Password [dba]: Default graph name [sesame:nil]: Enable using batch optimization (false|true) [false]: Use RoundRobin for connection (false|true) [false]: Buffer fetch size [200]: Inference RuleSet name [null]: Repository ID [virtuoso]: myvirt Repository title [Virtuoso repository]: Repository created show r . +---------- |SYSTEM |myvirt ("Virtuoso repository") +---------- open myvirt . Opened repository 'myvirt' myvirt> show n . +---------- |bif bif: |dawgt http://www.w3.org/2001/sw/DataAccess/tests/test-dawg# |dbpedia http://dbpedia.org/resource/ |dbpprop http://dbpedia.org/property/ |dc http://purl.org/dc/elements/1.1/ |foaf http://xmlns.com/foaf/0.1/ |geo http://www.w3.org/2003/01/geo/wgs84_pos# |go http://purl.org/obo/owl/GO# |math http://www.w3.org/2000/10/swap/math# |mesh http://purl.org/commons/record/mesh/ |mf http://www.w3.org/2001/sw/DataAccess/tests/test-manifest# |nci http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl# |obo http://www.geneontology.org/formats/oboInOwl# |owl http://www.w3.org/2002/07/owl# |protseq http://purl.org/science/protein/bysequence/ |rdf http://www.w3.org/1999/02/22-rdf-syntax-ns# |rdfdf http://www.openlinksw.com/virtrdf-data-formats# |rdfs http://www.w3.org/2000/01/rdf-schema# |sc http://purl.org/science/owl/sciencecommons/ |scovo http://purl.org/NET/scovo# |skos http://www.w3.org/2004/02/skos/core# |sql sql: |vcard http://www.w3.org/2001/vcard-rdf/3.0# |virtrdf http://www.openlinksw.com/schemas/virtrdf# |void http://rdfs.org/ns/void# |xf http://www.w3.org/2004/07/xpath-functions |xml http://www.w3.org/XML/1998/namespace |xsd http://www.w3.org/2001/XMLSchema# |xsl10 http://www.w3.org/XSL/Transform/1.0 |xsl1999 http://www.w3.org/1999/XSL/Transform |xslwd http://www.w3.org/TR/WD-xsl |yago http://dbpedia.org/class/yago/ +---------- exit.
Connection to Sesame HTTP repository from Console repository
The Sesame Console repository can connect to a Sesame HTTP repository and vice-versa, enabling access to remote Sesame HTTP repositories from a local server.
-
The Sesame Console repository can connect to a Sesame HTTP repository and query it as if local using the "connect" command.
$ sh console.sh SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/Users/myuser/openrdf-sesame-2.3.1/lib/logback-classic-0.9.18.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/Users/myuser/openrdf-sesame-2.3.1/lib/slf4j-jdk14-1.5.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 10:32:38.317 [main] DEBUG info.aduna.platform.PlatformFactory - os.name <http://os.name> <http://os.name> = mac os x 10:32:38.351 [main] DEBUG info.aduna.platform.PlatformFactory - Detected Mac OS X platform Connected to default data directory Commands end with '.' at the end of a line Type 'help.' for help > connect http://localhost:8080/openrdf-sesame. Connected to http://localhost:8080/openrdf-sesame > show r. +---------- |SYSTEM ("System configuration repository") |VirtSesRep ("Virtuoso Sesame HTTP Repository") +---------- > open VirtSesRep. Opened repository 'VirtSesRep' VirtSesRep> sparql select * from <http://localhost:8890/Northwind> where {?s ?p ?o} Limit 10. Evaluating query... +------------------------+------------------------+------------------------+ | s | p | o | +------------------------+------------------------+------------------------+ | <http://localhost:8890/Northwind/CustomerContact/ALFKI#this>| rdf:type | foaf:Person | | <http://localhost:8890/Northwind/CustomerContact/ALFKI#this>| rdf:type | northwind:CustomerContact| | <http://localhost:8890/Northwind/CustomerContact/ALFKI#this>| opl:isDescribedUsing | northwind: | | <http://localhost:8890/Northwind/CustomerContact/ANATR#this>| rdf:type | foaf:Person | | <http://localhost:8890/Northwind/CustomerContact/ANATR#this>| rdf:type | northwind:CustomerContact| | <http://localhost:8890/Northwind/CustomerContact/ANATR#this>| opl:isDescribedUsing | northwind: | | <http://localhost:8890/Northwind/CustomerContact/ANTON#this>| rdf:type | foaf:Person | | <http://localhost:8890/Northwind/CustomerContact/ANTON#this>| rdf:type | northwind:CustomerContact| | <http://localhost:8890/Northwind/CustomerContact/ANTON#this>| opl:isDescribedUsing | northwind: | | <http://localhost:8890/Northwind/CustomerContact/AROUT#this>| rdf:type | foaf:Person | +------------------------+------------------------+------------------------+ 10 result(s) (530 ms) VirtSesRep> show n. +---------- |SearchResults http://www.zillow.com/static/xsd/SearchResults.xsd |UpdatedPropertyDetails http://www.zillow.com/static/xsd/UpdatedPropertyDetails.xsd |a http://www.w3.org/2005/Atom |aapi http://rdf.alchemyapi.com/rdf/v1/s/aapi-schema# |address http://schemas.talis.com/2005/address/schema# |admin http://webns.net/mvcb/ |amz http://webservices.amazon.com/AWSECommerceService/2005-10-05 |atom http://atomowl.org/ontologies/atomrdf# |audio http://purl.org/media/audio# |awol http://bblfish.net/work/atom-owl/2006-06-06/# |aws http://soap.amazon.com/ |b3s http://b3s.openlinksw.com/ -
Conversely the Sesame HTTP repository can be configured to access the repository created by the Sesame console. To do this the location of the data directory for both needs to be reconfigured using the Java system property info.aduna.platform.appdata.basedir (does not include "OpenRDF Sesame console directory) to point to the same location. When you are using Tomcat as the servlet container then you can set this property using the JAVA_OPTS parameter. Note, if you are using Apache Tomcat as a Windows Service you should use the Windows Services configuration tool to set this property. Other users can either edit the Tomcat startup script or set the property some other way.
* set JAVA_OPTS=-Dinfo.aduna.platform.appdata.basedir=\path\to\other\dir\ (on Windows) * export JAVA_OPTS='-Dinfo.aduna.platform.appdata.basedir=/path/to/other/dir/' (on Linux/UNIX/Mac OS X)
Figure 16.199. Virtuoso Sesame HTTP Repository Configuration and Usage
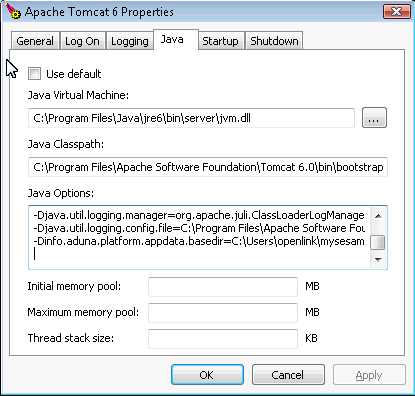
Remote Sesame HTTP Repository Connections
There are two methods of making a remote Sesame HTTP connection to a Virtuoso repository:
-
Sesame Remote Repository Manager
class - A manager for Repositorys that reside on a remote server, allowing one to access repositories over HTTP similar to how local repositories are accessed using the LocalRepositoryManager?. A connection via this method is made via the Virtuoso Sesame provider which will be faster and provide better support for transactions, than making a direct connection to the SPARQL endpoint using the HTTPRepository class. This is analogous to the ODBC Driver Manager in the ODBC realm for generic access to a data store via a suitable ODBC Driver.
-
Sesame HTTP Repository
class - A repository that serves as a proxy for a remote repository on a Sesame server or directly to a SPARQL endpoint. This method does not make use of the Virtuoso Sesame Provider, using instead the HTTP protocol to make requests directly Sesame server or other SPARQL endpoint.
Using the Sesame Remote Repository Manager class
If a Sesame HTTP Repository endpoint, as detailed above already exists, the Remote Repository Manager class can be used to make a remote connection as follows by specify the URL to the remote Sesame HTTP Server and the RepositoryID for the repository the connection is to be made to:
//Initialize Remote Repository Manager
RepositoryManager repositoryManager = new RemoteRepositoryManager( "http://hostname:portno/openrdf-sesame" );
repositoryManager.initialize();
//Set Virtuoso (or any other) repositoryID on http://hostname:portno/openrdf-sesame
Repository repository = repositoryManager.getRepository("RepositoryID");
// Open a connection to this repository
con = repository.getConnection();
// ... do something
Using the Sesame HTTP Repository class
A direct connection to the default built-in Virtuoso SPARQL Endpoint can be made using the Sesame HTTP Repository class by simply specifying the URL to the Virtuoso SPARQL Endpoint i.e. http://{hostname}:{port}/sparql as follows:
// Initialize Direct SPARQL Endpoint HTTP Repository connection String endpointURL = "http://hostname:portno/sparql"; HTTPRepository sparqlEndpoint = new HTTPRepository(endpointURL, ""); sparqlEndpoint.initialize(); // Open a connection to this repository con = sparqlEndpoint.getConnection(); // ... do something
Javadoc API Documentation
Sesame Provider Javadoc API Documentation is available enabling the complete set of classes, interfaces and methods implemented for the provider to be viewed.