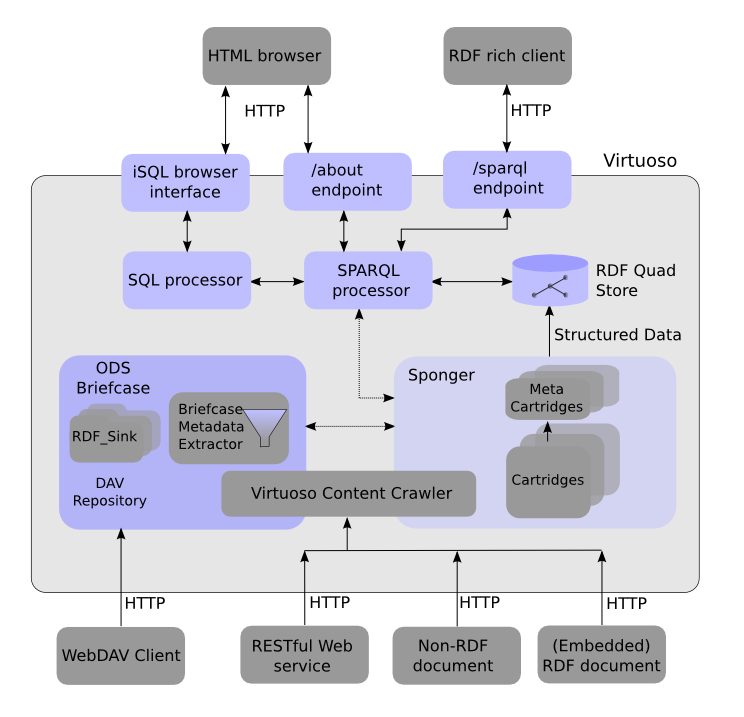
16.10. RDFizer Middleware (Sponger)
16.10.1. What Is The Sponger?
The Virtuoso Sponger is the Linked Data middleware component of Virtuoso that generates Linked Data from a variety of data sources, supporting a wide variety of data representation and serialization formats. The sponger is transparently integrated into Virtuoso's SPARQL Query Processor where it delivers URI de-referencing within SPARQL query patterns, across disparate data spaces. It also delivers configurable smart HTTP caching services. Optionally, it can be used by the Virtuoso Content Crawler to periodically populate and replenish data within the native RDF Quad Store.
The sponger is a fully fledged HTTP proxy service that is also directly accessible via SOAP or REST interfaces.
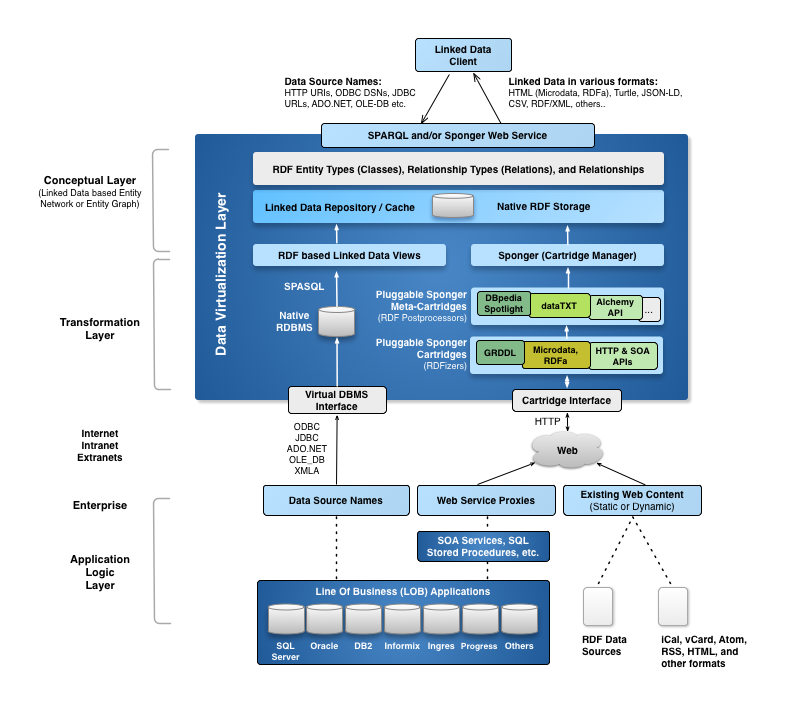
As depicted below, OpenLink's broad portfolio of Linked-Data-aware products supports a number of routes for creating or consuming Linked Data. The Sponger provides a key platform for developers to generate quality data meshes from unstructured or semi-structured data sources.
Figure 16.96. OpenLink Linked Data generation options
Architecturally, the Sponger is comprised of a number of Cartridges two types of cartridges: Extractor and Meta Cartridges. Extractor Cartridges focus on data extraction and transformation services while the Meta Cartridges provide lookups and joins across other linked data spaces and Web 2.0 APIs. Both cartridge types are themselves comprised of a data extractors and RDF Schema/Ontology Mapper components.
Cartridges are is highly customizable. Custom cartridges can be developed using any language supported by the Virtuoso Server Extensions API enabling structured linked data generation from resource types not available in the default Sponger Cartridge collection bundled -- as part of the Virtuoso Cartridges VAD package .
Figure 16.97. Virtuoso metadata extraction & RDF structured data generation