16.10.5. Using The Sponger
The Sponger can be invoked via the following mechanisms:
-
ODS-Briefcase (Virtuoso WebDAV)
- a component of the OpenLink Data Spaces distributed collaborative application platform
SPARQL Query Processor IRI Dereferencing
The Sponger is transparently integrated into the Virtuoso SPARQL query processor, where it supports IRI dereferencing.
Virtuoso extends the SPARQL Query Language such that it is possible to download RDF resources from a given IRI, parse, and then store the resulting triples in a graph, with all three operations performed during the SPARQL query-execution process. The IRI/URI of the graph used to store the triples is usually equal to the URL where the resources are downloaded from, consequently the feature is known as "IRI/URI dereferencing". If a SPARQL query instructs the SPARQL processor to retrieve the target graph into local storage, then the SPARQL sponger will be invoked.
The SPARQL extensions for IRI dereferencing are described below. Essentially these enable downloading and local storage of selected triples either from one or more named graphs, or based on a proximity search from a starting URI for entities matching the select criteria and also related by the specified predicates, up to a given depth. For full details see section Linked Data - IRI Dereferencing .
Note: For brevity, any reference to URI/IRIs above or in subsequent sections implies an HTTP URI/IRI, where IRI is an internationalized URI. Similarly, in the context of the Sponger, the term IRI in the Virtuoso reference documentation should be taken to mean an HTTP IRI.
SPARQL Extensions for IRI Dereferencing of FROM Clauses
In addition to the "define get:..." SPARQL extensions for IRI dereferencing in FROM clauses, Virtuoso supports dereferencing SPARQL IRIs used in the WHERE clause (graph patterns) of a SPARQL query via a set of "define input:grab-..." pragmas.
Consider an RDF resource which describes a member of a contact list, user1, and also contains statements about other users, user2 anduser3 , known to him. Resource user3 in turn contains statements about user4 and so on. If all the data relating to these users were loaded into Virtuoso's RDF database, the query to retrieve the details of all the users could be quite simple. e.g.:
sparql
prefix foaf: <http://xmlns.com/foaf/0.1/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
select ?id ?firstname ?nick
where
{
graph ?g
{
?id rdf:type foaf:Person .
?id foaf:firstName ?firstname .
?id foaf:knows ?fn .
?fn foaf:nick ?nick .
}
}
limit 10;
But what if some or all of these resources were not present in Virtuoso's quad store? The highly distributed nature of the Linked Data Web makes it highly likely that these interlinked resources would be spread across several data spaces. Virtuoso's 'input:grab-...' extensions to SPARQL enable IRI dereferencing in such a way that all appropriate Network resources are loaded, i.e. "being fetched", during query execution, even if some of the Network resources are not known beforehand. For any particular resource matched, and if necessary downloaded, by the query, it is possible to download related resources via a designated predicate path(s) to a specifiable depth i.e. number of 'hops', distance, or degrees of separation (i.e compute Transitive Closures in SPARQL).
Using Virtuoso's 'input:grab-' pragmas to enable sponging, the above query might be recast to:
sparql
define input:grab-var "?more"
define input:grab-depth 10
define input:grab-limit 100
define input:grab-base "http://www.openlinksw.com/dataspace/kidehen@openlinksw.com/weblog/kidehen@openlinksw.com%27s%20BLOG%20%5B127%5D/1300"
prefix foaf: <http://xmlns.com/foaf/0.1/>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?id ?firstname ?nick
where {
graph ?g {
?id rdf:type foaf:Person .
?id foaf:firstName ?firstname .
?id foaf:knows ?fn .
?fn foaf:nick ?nick .
optional { ?id rdfs:SeeAlso ?more }
}
}
limit 10;
Another example showing a designated predicate traversal path via the input:grab-seealso extension is:
sparql
define input:grab-iri <http://www.openlinksw.com/dataspace/kidehen@openlinksw.com/weblog/kidehen@openlinksw.com%27s%20BLOG%20%5B127%5D/sioc.ttl>
define input:grab-var "id"
define input:grab-depth 10
define input:grab-limit 100
define input:grab-base "http://www.openlinksw.com/dataspace/kidehen@openlinksw.com/weblog/kidehen@openlinksw.com%27s%20BLOG%20%5B127%5D/1300"
define input:grab-seealso <foaf:maker>
prefix foaf: <http://xmlns.com/foaf/0.1/>
select ?id
where
{
graph ?g
{
?id a foaf:Person .
}
}
limit 10;
A list of the input:grab pragmas is given below:
-
input:grab-var specifies the name of the SPARQL variable whose values should be used as IRIs of resources that should be downloaded.
-
input:grab-iri specifies an IRI that should be retrieved before executing the rest of the query, if it is not in the quad store already. (This pragma can be included multiple times).
-
input:grab-seealso (or its synonym input:grab-follow-predicate) specifies a predicate IRI to be used when traversing a graph. (This pragma can be included multiple times).
-
input:grab-limit sets the maximum number of resources (graph subject or object nodes) to be retrieved from a target graph.
-
input:grab-depth sets the maximum 'degrees of separation' or links (predicates) between nodes in the target graph.
-
input:grab-all "yes" instructs the SPARQL processor to dereference everything related to the query. All variables and literal IRIs in the query become values for input:grab-var and input:grab-iri. The resulting performance may be very bad.
-
input:grab-base specifies the base IRI to use when converting relative IRIs to absolute. (Default: empty string).
-
input:grab-destination overrides the default IRI dereferencing and forces all retrieved triples to be stored in the specified graph.
-
input:grab-loader identifies the procedure used to retrieve each resource via HTTP, parse and store it. (Default: DB.DBA.RDF_SPONGE_UP)
-
input:grab-resolver identifies the procedure that resolves IRIs and determines the HTTP method of retrieval. (Default: DB.DBA.RDF_GRAB_RESOLVER_DEFAULT)
SPARQL Processor Usage Example
Network Resource Fetch can be performed directly from within the SPARQL processor.
After logging into Virtuoso's Conductor interface, the following query can be issued from the Interactive SQL (iSQL) panel:
sparql
define get:uri "http://www.ivan-herman.net/foaf.html"
define get:soft "soft"
select * from <http://mygraph> where {?s ?p ?o}
Here the sparql keyword invokes the SPARQL processor from the SQL interface and the RDF data fetched from page http://www.ivan-herman.net/foaf.html is loaded into the local RDF quad store as graph http://mygraph .
The new graph can then be queried using the basic SPARQL client normally available in a default Virtuoso installation at http://example.com/sparql/. e.g.:
select * from <http://mygraph> where {?s ?p ?o}
RDF Proxy Service
The Sponger's functionality is also exposed via an in-built REST style Web service. This web service takes a target URL and either returns the content "as is" or tries to transform (by sponging) to RDF. Thus, the proxy service can be used as a 'pipe' for RDF browsers to browse non-RDF sources.
When the cartridges package is installed, Virtuoso reserves the path '/about/[id|data|rdf|html]/http/' for Sponger Proxy URI Service. For example, if a Virtuoso installation on host example.com listens for HTTP requests on port 8080 then client applications should use a 'service endpoint' string equal to 'http://example.com:8080/about/[id|data|rdf|html]/http/'. If the cartridges package is not installed, then the service uses the path '/proxy/rdf/'.
Note: The old Sponger Proxy URI Service pattern '/proxy/' is now deprecated.
Example 1
The following URLs return information about musician John Cale, gleaned from the MusicBrainz music metadatabase, rendered as RDF or HTML respectively. (The Network Resource fetched data is available in the HTML rendering through the foaf:primaryTopic property.)
-
http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/artist/72c090b6-a68e-4cb9-b330-85278681a714.html
-
http://demo.openlinksw.com/about/html/http/musicbrainz.org/artist/72c090b6-a68e-4cb9-b330-85278681a714.html
Example 2
The file http://www.ivan-herman.net/foaf.html contains a short profile of the W3C Semantic Web Activity Lead Ivan Herman. This XHTML file contains RDF embedded as RDFa. Running the file through the Sponger via Virtuoso's RDF proxy service extracts the embedded FOAF data as pure RDF, as can be seen by executing:
$ curl -L -H "Accept:application/rdf+xml" http://linkeddata.uriburner.com/about/id/entity/http/www.ivan-herman.net/foaf.html <?xml version="1.0" encoding="utf-8" ?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"> <rdf:Description rdf:about="http://linkeddata.uriburner.com/about/id/http/www.ivan-herman.net/foaf.html#Person1Stat"><scovo:dimension xmlns:scovo="http://purl.org/NET/scovo#" rdf:resource="http://rdfs.org/ns/void#numberOfResources"/></rdf:Description> <rdf:Description rdf:nodeID="b145981159"><rdf:rest rdf:nodeID="b145981158"/></rdf:Description> <rdf:Description rdf:about="http://linkeddata.uriburner.com/about/id/entity/http/www.mendeley.com/profiles/ivan-herman"><foaf:accountName xmlns:foaf="http://xmlns.com/foaf/0.1/">ivan-herman</foaf:accountName></rdf:Description> etc .. <rdf:Description rdf:nodeID="b145981130"><http-voc:elementName xmlns:http-voc="http://www.w3.org/2006/http#">text/html</http-voc:elementName></rdf:Description> </rdf:RDF>
(linkeddata.uriburner.com hosts a public Virtuoso instance.) Though this example demonstrates the action of the /about/id/entity/ service quite transparently, it is a basic and unwieldy way to view RDF. As described earlier, the OpenLink Data Explorer uses the same proxy service to provide a more polished means to extract and view fetched RDF data.
Usage of the Sponger Middleware via REST patterns
Delegation and proxies are part of the Internet and Web's federated architecture. Thus, developers of RESTful applications benefit immensely from the ability to leverage Sponger functionality via delegation to it as a proxy.
The following table presents list of the supported URL parameters:
Table 16.9.
| Parameter | Value | Description | Example |
|---|---|---|---|
| refresh | clean | Usage : for overwriting. The 'clean' usage explicitly clears the graph i.e. will cause the Sponger to drop cache even if it is marked to be in the fly. Thus, if fetched cache by some reason is left in some inconsistent state like shutdown during Network Resource fetching, then 'clean' is required as it doesn't check cache state. Note : must be used with caution as other threads may be doing fetching of network resources at same time. | Explicitly clear the graph |
| sponger:get | add | Usage : Add new triples to named graphs, progressively. This is the default value for the parameter sponger:get. May be used together with refresh=<seconds> to overwrite the expiration in the cache. | Add new triples and refresh on every 10 seconds |
| sponger:get | soft | Usage : Network Resource Fetch data subject to cache invalidation mode and associated rules of instance. May be used together with refresh=<seconds> to overwrite the expiration in the cache. | Network Resource Fetch data with option soft and refresh on every 10 seconds |
| sponger:get | replace | Usage : Replace subject to cache invalidation mode and rules, but coverage includes non fetched triples if such exist in a given named graph. may be used together with refresh=<seconds> to overwrite the expiration in the cache. | Replace data and refresh on every 10 seconds |
OpenLink RDF Client Applications
OpenLink currently provides two main RDF client applications:
ODE is a Linked Data explorer packaged as a Firefox plugin (support for other browsers is planned). iSPARQL is an interactive AJAX-based SPARQL query builder with support for SPARQL QBE, bundled as part of the OpenLink Ajax Toolkit (OAT). Both RIA clients utilise sponging extensively.
The ODE plugin is dual faceted - RDF data can be viewed and explored natively, through its integral RDF browser, or, as described above, rendered as HTML through ODE's 'View Page Metadata' option. The screenshots below show ODE's RDF browser being launched through the 'View Linked Data Sources' popup menu.
Figure 16.98. Launching ODE's RDF browser
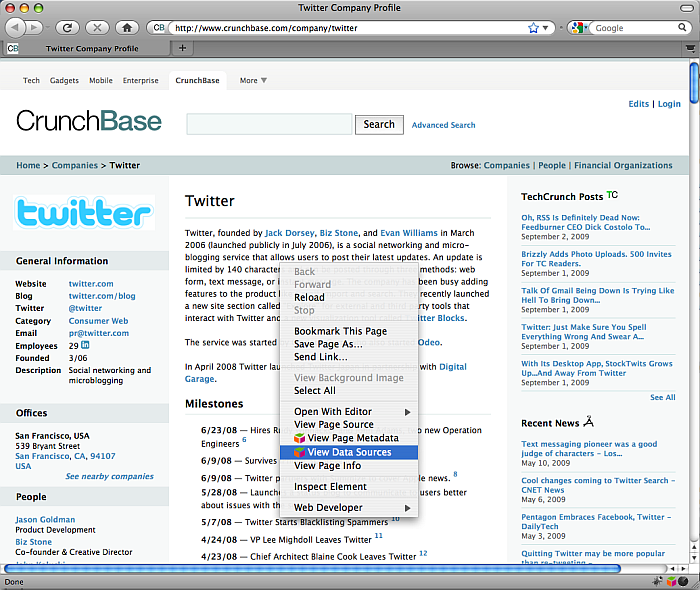
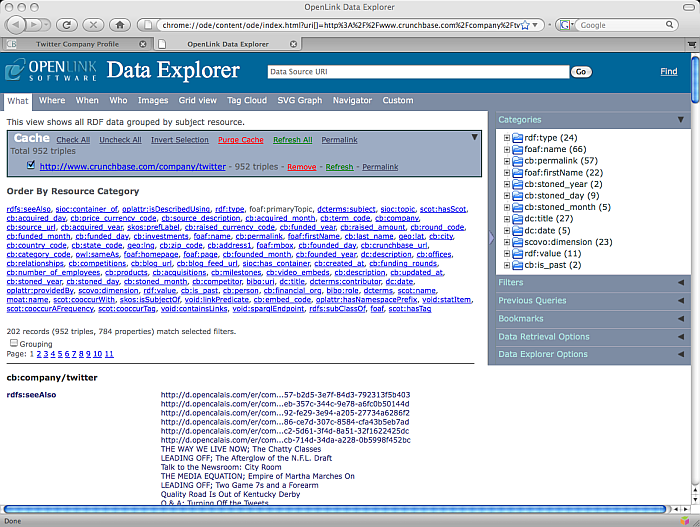
The RDF browser then displays RDF data fetched via the Crunchbase cartridge.
Figure 16.99. ODE RDF browser displaying Crunchbase network resource fetched data
iSPARQL directs queries to the configured SPARQL endpoint. When targetting a Virtuoso /sparql service, Virtuoso specific sponging options can be enabled through the 'Preferences' dialog box.
The iSPARQL sponger settings are appended to SPARQL queries through the 'should-sponge' query parameter. These are translated to IRI dereferencing pragmas on the server as follows:
Table 16.10.
| iSPARQL sponging setting | /sparql endpoint: "should-sponge" query parameter value | SPARQL processor directives |
|---|---|---|
| Use only local data | N/A | N/A |
| Retrieve remote RDF data for all missing source graphs | soft | define get:soft "soft" |
| Retrieve all missing remote RDF data that might be useful | grab-all | define input:grab-all "yes" define input:grab-depth 5 define input:grab-limit 100 |
| Retrieve all missing remote RDF data that might be useful including seeAlso references | grab-seealso | define input:grab-all "yes" define input:grab-depth 5 define input:grab-limit 200 define input:grab-seealso <http://www.w3.org.2000/01/rdf-schema#seeAlso> define input:grab-seealso <http://xmlns.com/foaf/0.1/seeAlso> |
| Try to download all referenced resources | grab-everything | define input:grab-all "yes" define input:grab-intermediate "yes" define input:grab-depth 5 define input:grab-limit 500 define input:grab-seealso <http://www.w3.org.2000/01/rdf-schema#seeAlso> define input:grab-seealso <http://xmlns.com/foaf/0.1/seeAlso> |
ODS-Briefcase (Virtuoso WebDAV)
ODS-Briefcase is a component of OpenLink Data Spaces (ODS), a new generation distributed collaborative application platform for creating Semantic Web presence via Data Spaces derived from weblogs, wikis, feed aggregators, photo galleries, shared bookmarks, discussion forums and more. It is also a high level interface to the Virtuoso WebDAV repository.
ODS-Briefcase offers file-sharing functionality that includes the following features:
-
Web brower-based interactions
-
Web Services (direct use of the HTTP based WebDAV protocol)
-
SPARQL query language support - all WebDAV resources are exposed as SIOC ontology instance data (RDF data sets)
When resources or documents are put into the ODS Briefcase and are made publicly readable (via a Unix-style +r permission or ACL setting) and the resource in question is of a supported content type, metadata is automatically extracted at file upload time.
Note: ODS-Briefcase extracts metadata from a wide array of file formats, automatically.
The extracted metadata is available in two forms, pure WebDAV and RDF (with RDF/XML or N3/Turtle serialization options), that is optionally synchronized with the underlying Virtuoso Quad Store.
All public readable resources in WebDAV have their owner, creation time, update time, size and tags published, plus associated content type dependent metadata. This WebDAV metadata is also available in RDF form as a SPARQL queriable graph accessible via the SPARQL protocol endpoint using the WebDAV location as the RDF data set URI (graph or data source URI).
You can also use a special RDF_Sink folder to automate the process of uploading RDF resources files into the Virtuoso Quad Store via WebDAV or raw HTTP. The properties of the special folder control whether sponging (RDFization) occurs. Of course, by default, this feature is enabled across all Virtuoso and ODS installations (with an ODS-Briefcase Data Space instance enabled).
Raw HTTP Example for Extracting Metadata using CURL
Username: demo Password: demo Source File: wine.rdf Destination Folder: http://demo.openlinksw.com/DAV/home/demo/rdf_sink/ Content Type: application/rdf+xml $ curl -v -T wine.rdf -H content-type:application/rdf+xml http://demo.openlinksw.com/DAV/home/demo/rdf_sink/ -u demo:demo
Finally, you can also get RDF data into Virtuoso's Quad Store via WebDAV using the Virtuoso Web Crawler utility (configurable via the Virtuoso Conductor UI). This feature also provides the ability to enable or disable Sponging as depicted below.
Sponger and ODS-Briefcase Structured Data Extractor Interrelationship
As the Sponger and ODS-Briefcase both extract structured data, what is the relationship between these two facilities?
The principal difference between the two is that the Sponger is anRDF data crawler & generator, whereas Briefcase's structured data extractor is a WebDAV resourcefilter. The Briefcase structured data extractor is aimed at providing RDF data from WebDAV resources. Thus, if none of the available Sponger cartridges are able to extract metadata and produce RDF structured data, the Sponger calls upon the Briefcase extractor as the last resort in the RDF structured data generation pipeline.
Figure 16.100. Conductor's content import configuration panel
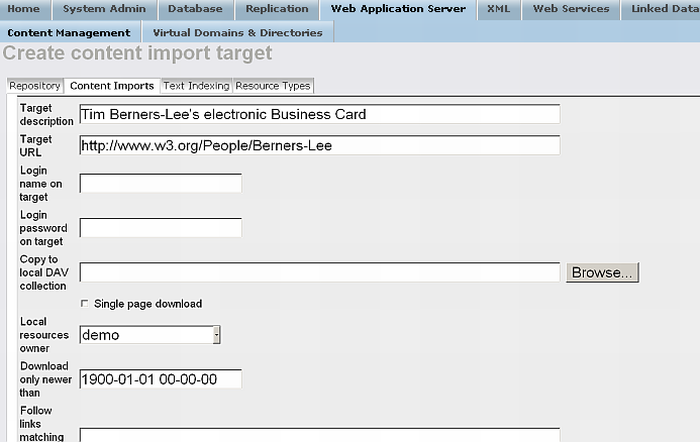
Figure 16.101. Conductor's content import configuration panel
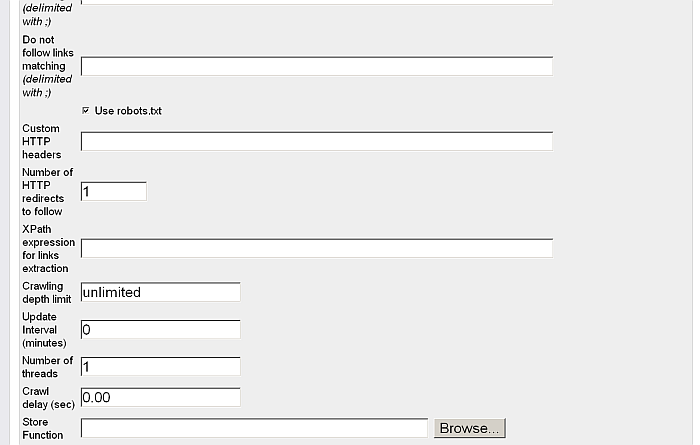
Figure 16.102. Conductor's content import configuration panel
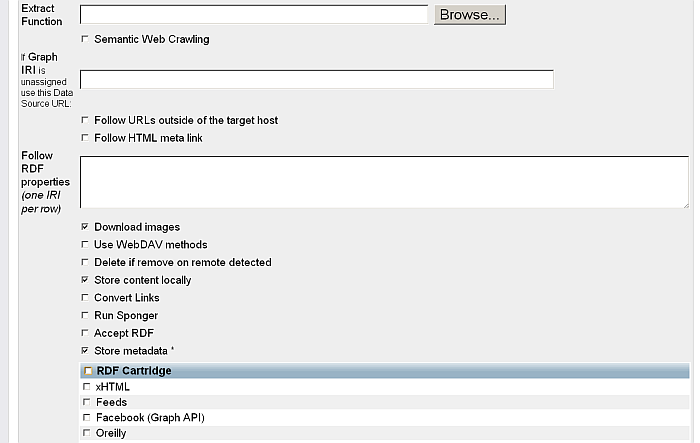
Figure 16.103. Conductor's content import configuration panel
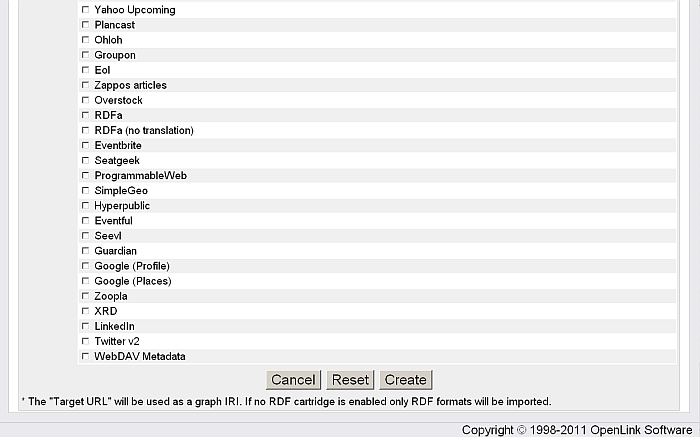
Directly via Virtuoso PL
Sponger cartridges are invoked through a cartridge hook which provides a Virtuoso PL entry point to the packaged functionality. Should you wish to utilize the Sponger from your own Virtuoso PL procedures, you can do so by calling these hook routines directly. Full details of the hook function prototype and how to define your own cartridges are presented here .